
A new SQL function - QUALIFY! And How To Optimize A Query Run Time - Issue 57
SQL window function QUALIFY, its use-cases, and overview of SQL optimization practice

Hot off the presses, here’s a new fancy SQL function for your enjoyment today - QUALIFY.
To be fair, this function is not new and has been around for ages, originally coming from Teradata and available today in Oracle and Snowflake. I just happened to discover it this week while dealing with a Snowflake SQL problem and it blew my mind! This allows you to do complex aggregations while significantly reducing query run time.
In this issue, I’ll demonstrate an example of how QUALIFY helps you optimize your SQL, how it is better than HAVING, and go over some SQL cost/time optimization challenges.
How QUALIFY works
To start with, QUALIFY is very similar to HAVING and WHERE and simply filters further ordered rows or performs aggregations. The main difference between QUALIFY and HAVING is that the former filters multiple ordered functions. It allows the execution of complex window functions without affecting query run time.
Examples
Before I learned about QUALIFY, I’d normally create a window function (like ROW_NUMBER or RANK) in a subquery which I’d call in a WHERE clause in the upper query to filter records. Like I did in the User Activity Analysis in this SQL, I used the RANK() window function to locate the most popular user activity across all users.
Or in another example, let’s say I want to locate the top payer in my user base segmented by product type. Here is one way to do it using a subquery and ROW_NUMBER() function:
SELECT product_type, user_id, paid_price
from (
SELECT product_type,
user_id,
ROW_NUMBER() OVER (PARTITION BY product_type ORDER BY paid_price DESC) AS row_num,
DISPLAY_PRICE
FROM users
)
WHERE row_num = 1You can simply this logic a lot by applying QUALIFY which would transform the query to:
SELECT product_type,
user_id,
paid_price
FROM users
QUALIFY ROW_NUMBER() OVER (PARTITION BY product_type ORDER BY paid_price DESC) = 1This query does the same job as the previous one, but is more optimal for the cost and execution time.
SQL optimization methods
Optimizing query performance time is important and demonstrates your knowledge of RDBS. SQL optimization techniques are my favorite interview questions, especially at small companies where every analyst has access to a production database and has the freedom to run any SELECT queries. Slow or failing SQL queries may cause more damage and slow down whole database performance or reduce its efficiency.
While SQL tuning is more a data engineering topic, every analyst must have an understanding of how indexes work and know basic and simple query optimization techniques.
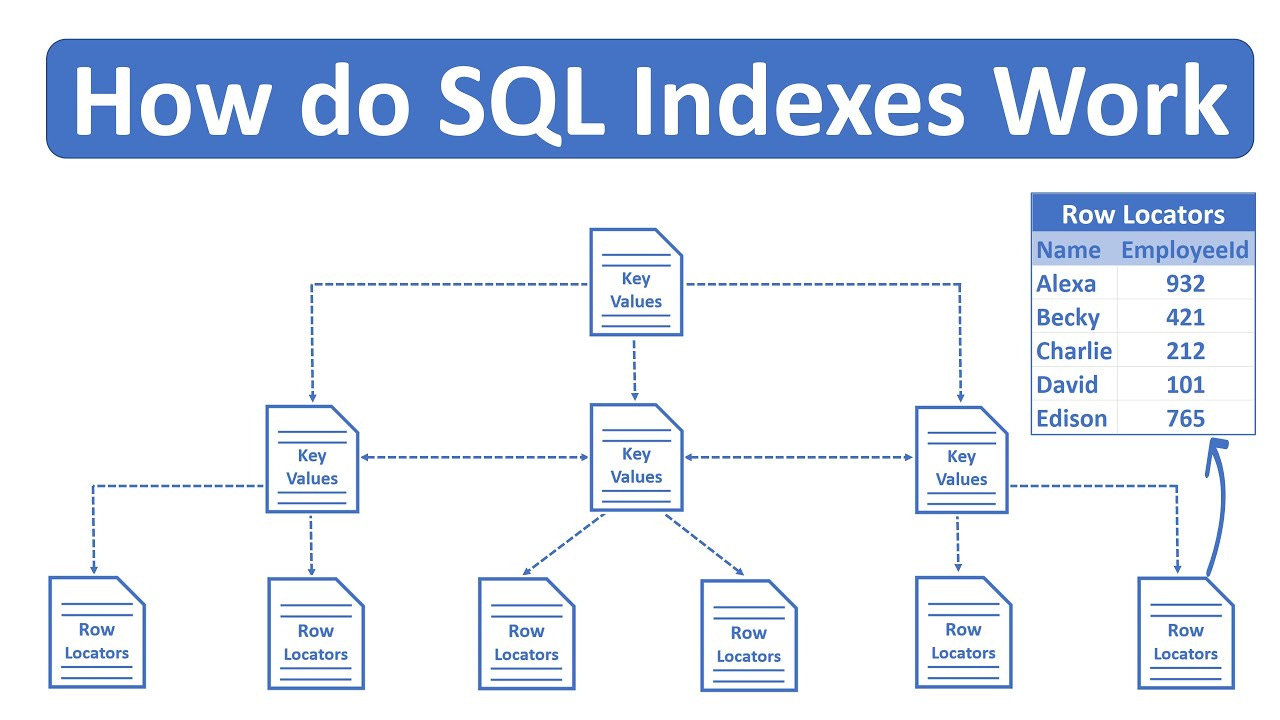
Taken from YouTube video - How do SQL Indexes Work, one of the best index explanations I have come across.
If you are asked during your interview about best practices of query optimizations, this is what you should mention:
Avoid use SELECT * but rather list the columns you need
Avoid SELECT DISTINCT if you can
Apply filter with WHERE and not HAVING
Use LIMIT to cup your query results
Avoid using sub-queries
Avoid using OUTER JOINs
Avoid using cross joins (which are the most expensive)
If you are a data engineer or DBA, I would expect you to be able to explain the logic behind these.
How QUALIFY function helps optimize SQL
As of now, SQL allows window calculations only in the SELECT (and ORDER BY in some SQL variations). This means that window functions are evaluated after the FROM, WHERE, GROUP BY, and HAVING clauses. You can use a subquery to perform needed filtering (as I did in my first example), however, this adds a layer of complexity to the execution time and cost. QUALIFY allows referring to window calculations directly without the need for a table expression.
This is how SELECT statement execution order works:
FROM
WHERE
GROUP BY
HAVING
SELECT
ORDER BY
This explains why HAVING is more costly than WHERE, and why window functions in the SELECT are more expensive than using QUALIFY because of the latter acting like WHERE or HAVING.
While these are all useful features, the bad news is that QUALIFY is available only in Snowflake and Oracle now (and Teradata). In Postgres or SQLserver you would still need to apply alternative solutions like aggregates and a subquery. However, I imagine that this will all be integrated before too long, and this function will be supported everywhere.
Here are links to the original QUALIFY documentation:
Thanks for reading, everyone. Until next Wednesday!