
Applying ML in Product Analytics - Issue 131
Using machine learning to solve common challenges in product and data analytics. How to figure out which model to use for which business case.

“You don’t have to know the code, but you do need to know what the code can do.”
from Stanford DS School
There are over 50 types of machine learning algorithms with different levels of complexity, similarity, and application.
How many of these 50 models will you realistically be developing for your projects?
In fact, mostly two: Linear Regression and Random Forest. Joking! …Or am I?
With so many algorithms out there, it can be challenging to figure out which model to choose for your analysis (or if you even need to use one at all). This week’s publication is a continuation of What Statistics Are Used In Data Analysis?, and is also an introduction of sorts to Machine Learning 101 (but aimed at analysts).
In today’s publication, I’ll share a guide to help you decide which ML model to pick to solve a problem, and how deep into the woods you’ll need to go with statistics to create a customer churn prediction model or forecast subscription revenue.
To start with, here’s a quick recap of the main types of ML algorithms:
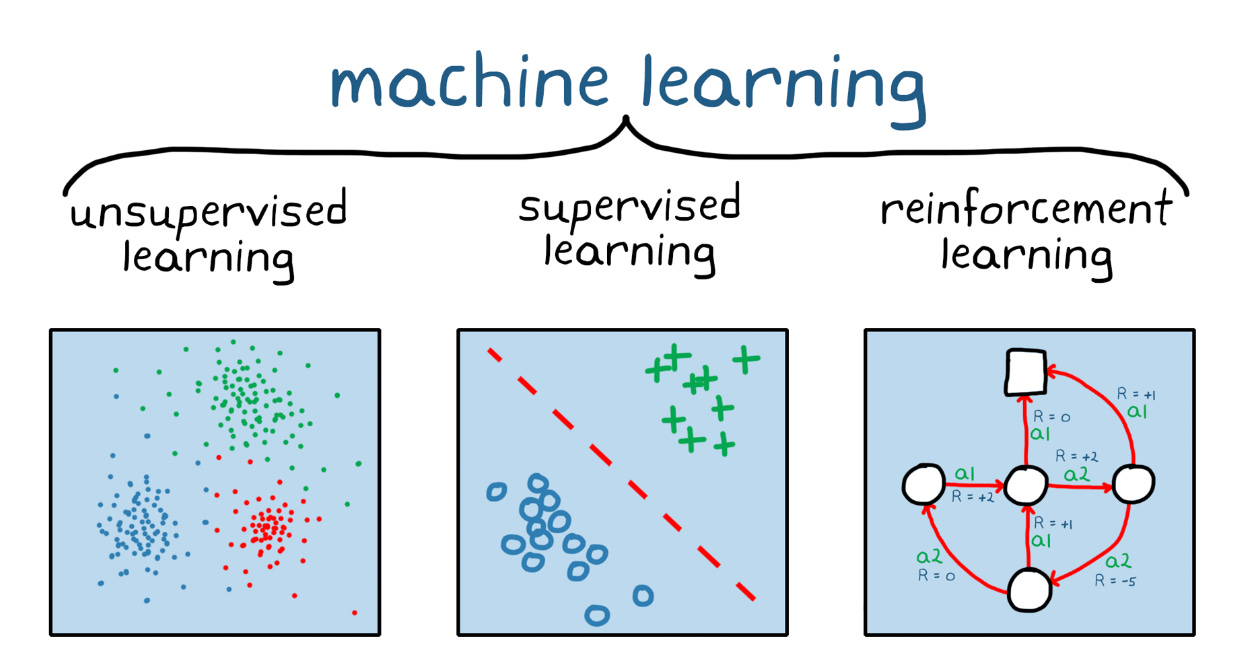
Supervised learning - You know how to classify the input data and the type of behavior you want to predict, but you need the algorithm to calculate it for you on new data. The data you work with is labeled, tagged, and has all the inputs and outputs. If you are an analyst, 98% of your work will stay here.
Unsupervised learning - You do not know how to classify the data, and you want the algorithm to find patterns and classify the data for you. A lot of things are happening here. Algorithms process a large volume of data and organize it into clusters (mostly) or some type of structure. The more data you pipe in, the more precise and refined the model will be. If you are a lucky analyst, 2% of your work will be in unsupervised learning, mostly around clusters and recommender systems.
Semi-supervised learning - The line between unsupervised and supervised learning is blurry. Often you have to work with a mix of labeled and unlabeled data. The algorithms use available tags to learn and then mark unlabeled data. This is for cases where you have to use all available data, not only labeled. This also includes even partially labeled data, and you have to make it work for the whole volume.
Reinforcement learning - You don’t have a lot of training data; you cannot clearly define the ideal end state, or the only way to learn about the environment is to interact with it. These algorithms work as an ecosystem that is built on a “trial and error” approach. They learn from errors in already-processed data, adapt, and look for the best result over and over again.
Using Supervised ML for data analysis
Because it’s all about analytics here, I’ll try to list the most common models used in data analytics and layout use cases for each.
There are 4 main outputs and the type of analysis we are expected to work with:
Regression
Classification
Clustering (unsupervised)
