
SQL: Data Sampling in RedShift
Working with big data you often have to apply different sampling techniques for your analysis. Here is one simple way to do it.

Working with big data you often have to apply different sampling techniques for your analysis — select a representative subset of data to identify patterns and trends in the larger data set. For example, if you need to pull a subset of some type of returning/not active/churned/etc users for a specific product and then to profile them, or simply randomly choose some user distribution % for any deep-dive analysis.
While there are many sampling techniques, I am going to describe below one of the simplest ways to get a randomly distributed data set from RedShift.
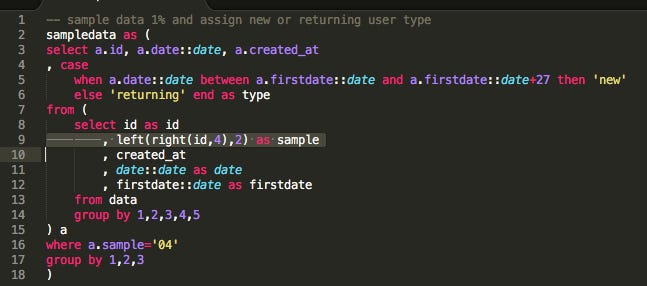
In the code below, I select a random sample of user ids based on their id corresponding number in the system:
The sampling is happening in a subquery line 9 :
left(right(id,4),2) as samplefollowed by sample = "04" in the outer query:
The code is here.
You can set any other corresponding number, and it will fetch only users with 04 sequential number in their user id value.
This method will work if user id data is inserted and stored in a table sequentially (incrementally), for example: userid = 100001, 100002, 100003, 100004, …. And theoretically, you want to fetch from this column only users with “04” or any other corresponding number depending on the volume of your data. It will return you, for example, userid = 100004, 100104, 101004, 110004 etc. depending on your parameters.
Additionally, in a CASE statement, I am also assigning the appropriate user type as “new” or “returning” dividing my data into 2 subsets (in my analysis later I’ll work on profiling and comparing them):

Make sure user ids are randomly sampled across the table you are using, and do not rely on a specific product feature that might affect your analysis. This method is simple and fast and works well in PostgreSQL. You can also get data sampled through NEWID or TABLESAMPLE described here.