
How To Measure Your Adjacent Users - Issue 130
A practical guide on how to locate and measure a tricky product persona of adjacent users in SQL, and challenges of getting such analysis in product analytics tools

In 2020 the product growth world was disrupted by a sensational guest post on Andrew Chen's blog - The Adjacent User Theory, written by Bangaly Kaba, a Reforger and Former VP Growth @Instacart, Instagram. It quickly was picked up and referenced by every trendy growth advisor, reposted, and republished almost too many times across Reforge, ProductLed, Medium, UserPilot, Y Combinator, and more (including yours truly).
It was (and still is) “big” because it pointed to both the painful and the obvious by offering examples, and also provided a framework to follow to scale your growth, nicely structured and backed up with data. It was not entirely new, as the concept of these users was around for many ages across many marketing books, publications, and blogs (Paul Graham, Patrick Collison, Avinash Kaushik, to name a few). But once it gets a weird name, a few unicorn references, and a round funnel (pardon me: loop chart), it quickly becomes a new successful “theory” and a playbook with a proven record of hacking the growth.
It inevitably affected product analytics, as every PLG-determined product owner began scraping their analytic tool to locate these adjacent users to answer what exactly doesn’t work for them and why that might be. Failing to find the right cohorts, they looked to their brave and brilliant analysts with a request to locate, estimate, and pull these users for a deep-dive study across their demographics, behavior, attributes, and tenure.
Finding these users, even for experienced analysts, is not simple or intuitive. It requires a thorough understanding of a user base, its dynamics, and user behavior, but foremost: having matured analytics in-house to provide you with sufficient user attributes. This is often not a luxury to have at small and even mid-size companies, not to mention the historical data you need to have for defining your personas.
I think I went through every article, reference, tweet, and post on adjacent users from trendy growth advisors and hobbyists out there. As expected, there was a flood of opinions about “what” and “why”, but not a single practical guide on “how”. So here it is! My walkthrough and solution (in SQL because after many months of trying I couldn’t figure out a trusted way to do so in product analytics tools) on how to locate those malicious adjacent users in your userbase. I’ll then take a look at why product analytics tools still fall short to support you in such analysis.

To recap: who are Adjacent users, and why are they important?
An adjacent user is a product persona along with power, core, casual, activated, new, and visitors personas that make up your whole user base. This is a group of users who know about your product but haven’t become engaged users yet.
Some quick takes from Bangaly Kaba:
Adjacent users are aware of and have possibly tried using the product, but are not able to successfully become engaged users.
This is typically because the current product positioning or experience has too many barriers to adoption for them.
Building empathy for the adjacent user is hard because, by definition, your team is not living the experience of the adjacent user. Your team are power users of the product.
The most successful companies are the ones that can continuously evolve to serve more adjacent users. The art is selecting the right groups of adjacent users to go after next.
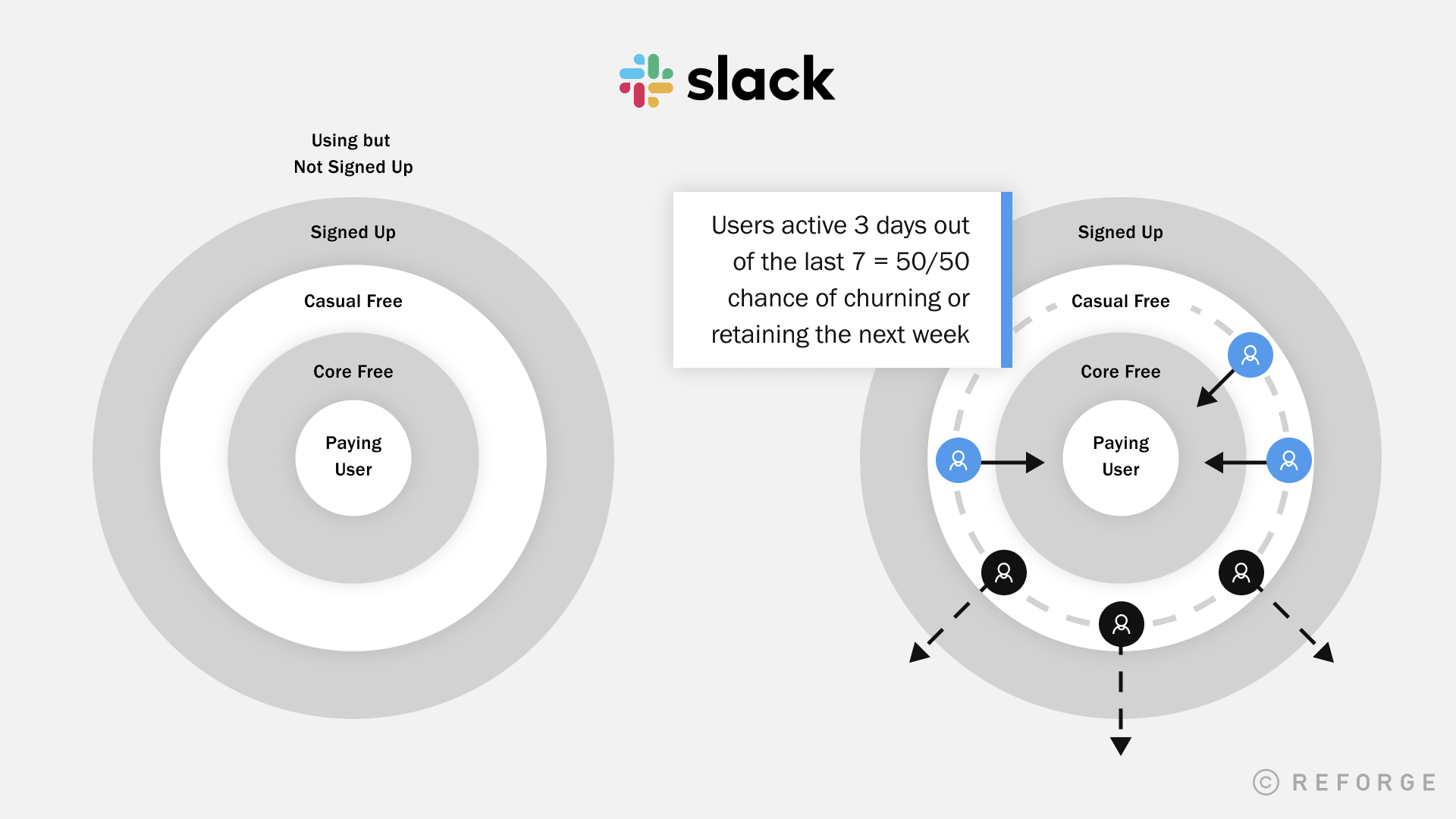
The adjacent user is critical to locate and measure because it helps you capture the full potential of your product marketing positioning.
To convert the adjacent Users into your power Users, you have to know who is successful today and why. This gives you a number of user characteristics that help you to differentiate the “powerful” category from the adjacent one.
Here are four techniques Bangaly recommends:

Why adjacent users are challenging to locate using product analytics tools
It’s a hit-or-miss to leverage product analytics tools today, like Amplitude, Heap, or Mixpanel to locate and define your adjacent users. Even assuming that (a) your analytical setup is rich and (b) you have all the activity events and properties you need, and (C) you also have enough historical data for all the events, you still face multiple challenges with this specific cohort:
1. Adjacent users group is mixed
Unlike other product personas, the adjacent users group is mixed.
By its definition, this group is across different stages of your product lifecycle (e.g it’s in your signup funnel, activation funnel, top features, rare-used features, paid subscriptions, free usage, etc) You can’t simply pick a specific event, and list a few user attributes and wrap it in a cohort group (like you would do with the activated or core users). You literally have to select every event you have with every user property your analytics has. You probably don’t want to use “any active event” (as a common option) because login, app open or screen view won’t be sufficient. You would need to create a custom event and come up with over-complicated dates logic to figure out the right frequency of usage.
2. Adjacent users group is dynamic
As I said above, this group will contain all types of users you pull into your funnel with various attributes and properties. In my experience, you will need to leverage more user properties instead of event properties to define a cohort.
The common challenge with user properties is that you can have only one value per user for a particular event. So you have to set the logic for which value to pick up - (1) the initial one or (2) the latest one. Both cases are bad for analytics:
Case 1: the initial value will stay the same for that user and won’t be overridden by the most recent value.
Case 2: the latest value will override the previous value for that user.
For example, let’s say a user purchased a paid subscription. The user property in your analytics might be user_status = paid. Then let’s say a user canceled a subscription, so the new user property value for that user will be updated (hopefully, if you do Case 2 above) to user_status = free. So now, in your analytics, this user will be shown as free. Often, there is no way for you to see if this user ever was a paid customer before in your funnel or a cohort. Or there is no way to specify - this user never was a customer. Having these filters is crucial to locate our group.
3. Adjacent users group is large
This might not be a concern for your team or product, depending on your plan and the volume of events, but it was very much a constraint for multiple clients I worked with.
Be prepared, for unlike power or premium users, the group of adjacent users is large. I believe this is one of the largest personas you have to aim for when iterating your product. You might not be able to simply export it and pass it to your marketing or research teams for further study. You won’t be able to pull a list of different characteristics for these users all at once, too.
4. You can’t check yourself
The challenge with creating product personas is that you must be imbued with the highest confidence that users in your group share similar characteristics. That’s the whole purpose of personas - finding randomly distributed users who share something common with each other.
To validate that your users are correctly grouped, you need to run them against multiple attributes to ensure exactly these 5K users all have a specific event on X day, X week, using X feature, having X number of actions, etc. The only way to do it in Amplitude or similar tools is to look up a specific user and open a log of their activity and endlessly browse through hundreds of events hoping to find THAT one. There is no way of doing so for a group of users.
When product tools fall short of flexibility and trust, old-fashioned data analytics comes to the rescue. Is that a bird? A plane? A nonsensical spreadsheet? No. It’s SQL, here to save the day (and your analytics).
