
Structuring Data & Analytics Teams for Real Impact - Issue 291
How org structure shapes analytics insight, governance, and the quality of every decision.

Welcome to the Data Analysis Journal, a weekly newsletter about data science and analytics.
I waited a long time to write about data team structure, mostly because many analysts don’t formally control how teams are organised. But the uncomfortable truth that many don’t say out loud is that where your analytics function sits often determines the impact you’re able to make.
If you land in Product, you’re close to experimentation and growth. Land in Finance, and you’re pulled into forecasting and reporting. Land in Marketing, and you may never touch core product metrics or engagement analytics at all. Land in Data or Data Science, and you have a chance to develop models and work with ML.
The structure around you - tooling, ownership lines, collaboration patterns, and even who reviews your work, often shapes the kind of problems you’re allowed to solve. It dictates whether your insights influence decisions or get stuck in a backlog. Unfortunately, we have all seen strong analysts effectively silenced by deprioritized projects, cut off from decision-makers, or never given a seat at the table, or even a chance to earn one. The organization, and particularly the structure of the data and analytics function, doesn’t always create equal opportunity for everyone.
Today, I want to break down common data team structures, their pros and cons, and offer guidance on what you can do to maximise your impact - and ensure data becomes the foundation for every decision, no matter which structure you land in.
Why structuring data and analytics teams is difficult
Unlike design, engineering, or customer success, data and analytics are the hardest functions to structure:
The analytics “function” is neither purely engineering nor purely business-facing. It sits somewhere between of everything. It may report to Finance, Product, Marketing, Business Development, HR, Engineering, or a C-suite (depending on the org).
The operating model needs to evolve as the company scales. What works at 10 people breaks at 100 or 1K.
There are competing priorities: speed vs governance, domain knowledge vs standardisation, local context vs enterprise consistency.
Here is how companies typically structure data teams:
Centralized Model
In the fully centralized model, a single analytics/data team owns everything: ingestion, transformation, modelling, analytics, and reporting. All analysts, data engineers, and data scientists sit in one department, and business units make requests to that team:
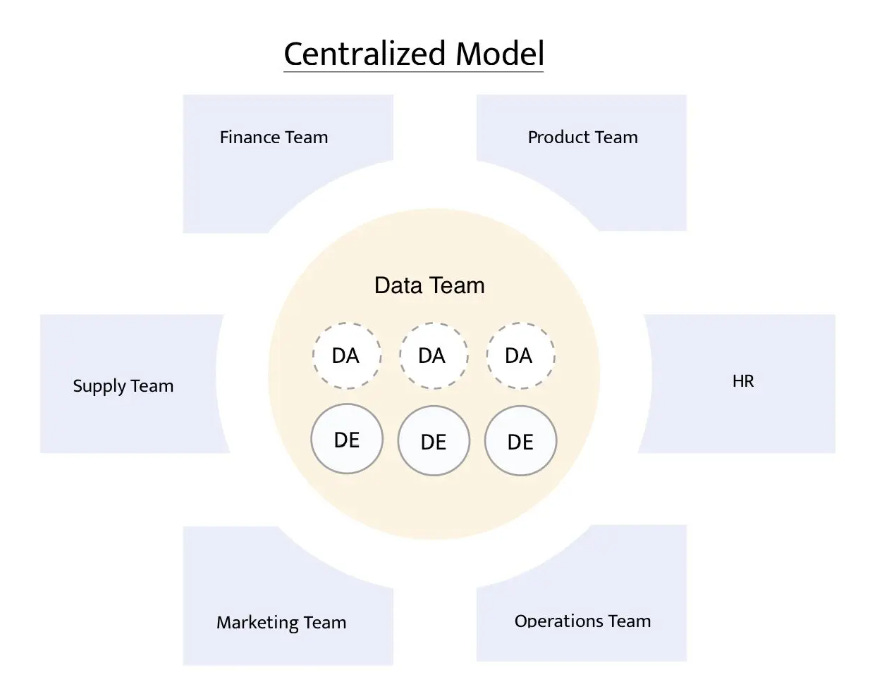
This is most common for enterprises and large companies that deal with compliance, finance, or health data.
Pros: Strong data governance, common standards and guardrails, shared naming, metrics, and code reviews. Easier knowledge sharing between analysts and engineers. Everyone is on the same page with what definitions are used for what, which tables and schemas to access, and so on.
Cons: Potential bottleneck: business stakeholders must queue requests and wait. Speed suffers. The central team may lack context of each team's challenges and needs. Getting requirements takes time, dashboards have low adoption, metrics are lost in transactions, and there is often a gap between what’s requested/asked vs what the data team can offer.
