
Binary logistic regression overview
Common use cases for logistic regression and walk through the steps of applying it for data forecasting.


Predictive modeling (or machine learning) can be challenging to understand and use because there is no one algorithm that would work the best for every problem. Therefore, you have to apply different methods for your prediction, evaluate their performance, and only then select the strongest algorithm. In this article, I will go over some use cases for logistic regression and walk through the steps of applying this classification algorithm for data forecasting.
Factors to consider before choosing the algorithm
Before applying a specific type of algorithm, you have to consider and evaluate the following factors: parametrization, memory size, over-fitting tendency, time of learning, time of predicting, etc. You choose classification models over regression models when your target variable is categorical (and not numerical). Therefore, you would apply logistic regression for the following types of predictions:
Will a student pass or fail the class?
Is email spam or not?
Which samples are false or true?
What is a person’s sex based on their height input?
All of these are probability predictions, but their output has to be transformed into a binary value of 0 or 1 for logistic regression (you can read more about logistic regression here).
Predictive modeling steps
I’ll walk through predictive modeling using the Titanic challenge. There are two datasets that include real Titanic passenger information like name, age, gender, social class, fare, etc. One dataset, “Training,” has binary (yes or no) data for 891 passengers. Another one is “Testing” for which we have to predict which passengers will survive. We can use the training set to teach our prediction model with the given data patterns, and then use our testing set to evaluate its performance. I’ll use Python Pandas, Seaborn statistical graph, and Scikit-learn ML package for analysis and modeling.
1. Problem definition
We begin with defining our problem and understanding our target variable is and what features we have available. In our case, we want to predict which Titanic passengers will survive.
2. Exploratory data analysis
We begin with Exploratory Data Analysis to understand the dataset, its patterns, and which features we will use for Logistic Regression:
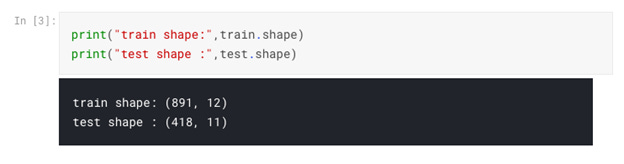
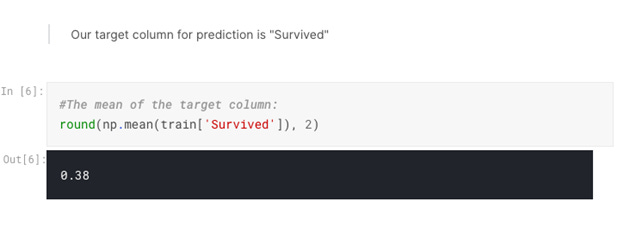
This tells us how big our datasets are, and we can see that the Train set has one more column. This is our target “Survived” value. Now, let’s take a look into gender data broken down by survival category:
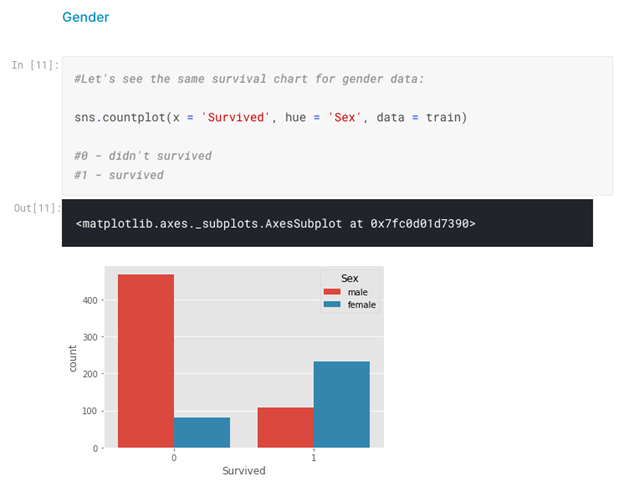
We can see that women are more likely to survive. We have to run more analysis for other input features like age, social class, family size. You can see full EDA here.
3. Feature engineering
Before we proceed with modeling, some feature engineering has to be done — preparing our data for prediction. We start with transforming categorical values into numerical:
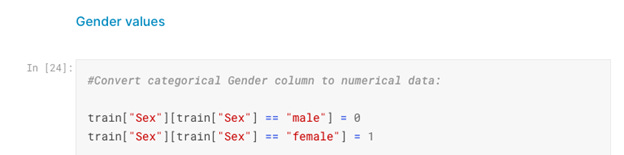
Now, we have to fill missing values for Age, Embarked, etc. features:
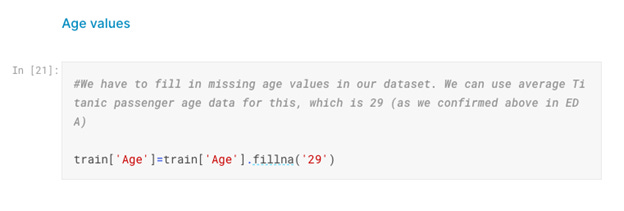
And the last step will be to drop values we won’t be using for our prediction:

4. Prediction
We begin by defining our X and Y-axis. We also will use a test split feature, and will run the forecast for 20% of our sample:

And, predicting!
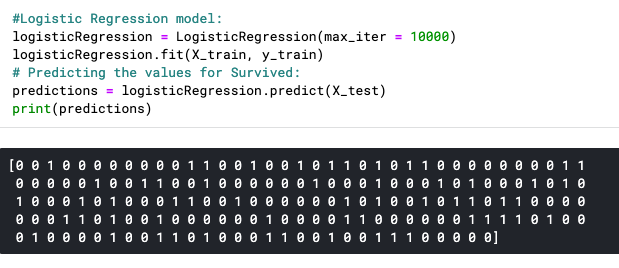
As we expected, the prediction returned a binary value 0 or 1 for every passenger in our set, which stands for 1 — Survived, 0 — Didn’t Survive.
5. Model evaluation
Now, let’s check the accuracy score to evaluate algorithm performance:
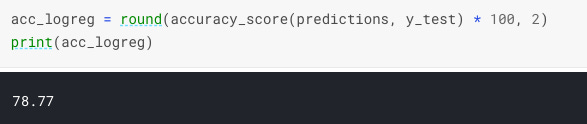
Not bad, having only a few features as an input, our prediction model has 78% accuracy. We can increase the accuracy score by doing more feature engineering to extract the most value from the input features.

This was a quick step by step guide on how to apply logistic regression for data prediction. There are other machine learning models that might return a higher accuracy score for a given problem. But remember, the algorithms we apply must be appropriate for the task given the set of input features we have like memory size, data structure, etc. Logistic regression demonstrates the advantage of a simple and fast model that is also powerful, interpretable, and explainable.
Hi Olga, thank you for your article.
Do you mind please share some materials on ways to improve logistic regression when dealing with imbalanced dataset? i.e. my problem is that only 5% of observations have the value of 1, and the rest is 0. How should I approach cases like this? Thank you.