
5 Mistakes To Avoid When Running A/B Tests - Issue 31
Common product test mistakes and a practical guide for successful A/B tests

Many companies today are very aggressive in running product tests. Some make testing part of their culture, and some simply use it as a security tool to validate new features. Regardless of the company mission, values, or roadmap agenda, as a data or product analyst, you have to ensure your team follows the right test principles, ethics, and statistical foundation.
Here are some common mistakes and misunderstandings approaching A/B tests. Make sure you catch these early in the process to prevent data bias, irrelevant evaluation, or incomplete results.
If you are getting started with A/B tests, make sure to read the A/B One-Pager Checklist - a short guide to steps and must-know terminology.
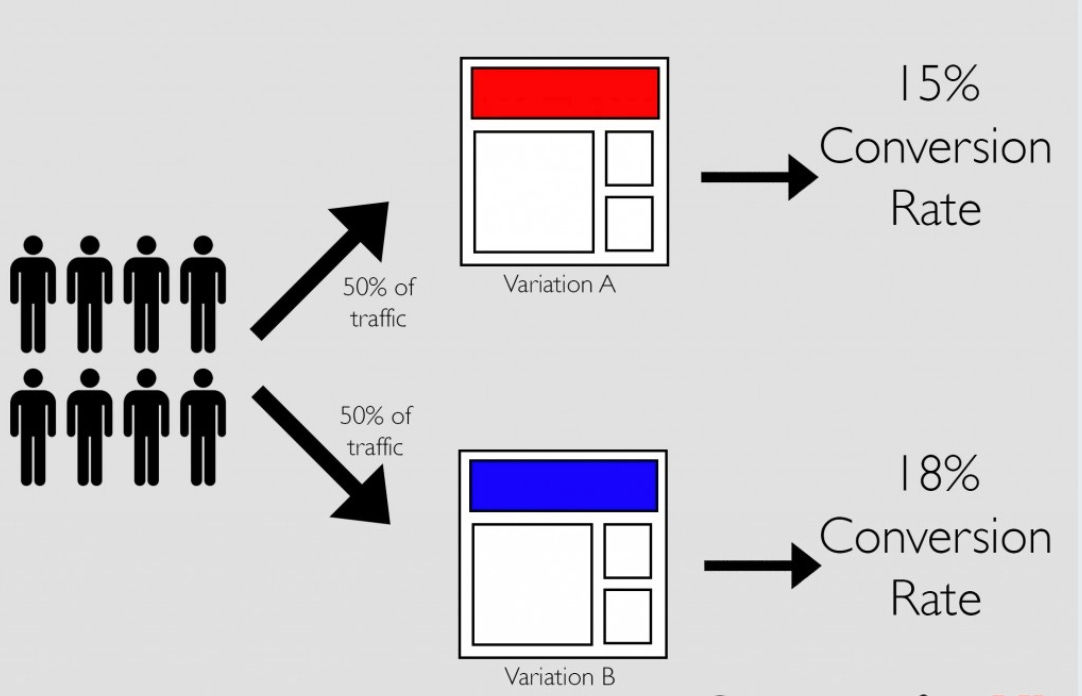
image credit to cxl
Mistake 1: not having a hypothesis ready
Product tests have different variations: A/B, A/A, MVT, split-URL, multi-page. One common thing that unites all tests above is hypothesis testing. Therefore, you have to start with a hypothesis first: what do you test against or what change do you want to prove or reject?
For example:
Null hypothesis: the floating button does not cause at least 10% more clicks than the raised button.
Alternative hypothesis: the floating button does cause at least 10% more clicks than the raised button.
This can be applied to CTAs, subject lines, design layouts, user flows, or even new features.
Mistake 2: not setting MDE before the test launch
MDE means Minimum Detectable Effect. It stands for the percentage of change you expect to see (for example, 10% more clicks). You must have MDE set to estimate the test timeline and significance. If MDE is small, you would need a large sample to detect the effect.
If your baseline conversion is 20%, you may set the MDE to 10%, and the test may detect 18% - 22% conversion results.
Mistake 3: not knowing your success metric
This is the most common mistake with A/B tests. The product test aims to improve a conversion in order to increase a product metric which should be reflected in one of your KPIs and lead to either increased revenue or growth. Make sure that you establish a connection between your conversion and the product metric.
For example:
10% more CTA clicks increase the signup rate twice. This change improves 1% user growth or user acquisition.
10% more clicks from the new payment layout increase the upgrades rate. This change potentially can improve new business MRR by 2%.
For such estimation, you should know the baseline metrics (or Control conversion) before the test launch. Therefore, make sure you can measure the metrics you want to influence: MAU definition, churn calculation, growth conversion, etc.
Similarly to MDE, the deeper in the product funnel that the change is that you want to test, the larger the sample size you will need.
Mistake 4: not estimating the test timeline
This is tied to Mistake 2 and 3 described above. Knowing your MDE and Baseline conversion metric, you can estimate the test timeline to reach significance and determine the test cost and effort. Depending on what data you have, how is it distributed, and what change you expect to see, there might be no appropriate timeline for your test to reach significance. It’s often recommended to run the experiment for 2 business cycles (2-4 weeks), but not every experiment fits this life pattern. Therefore, make sure to warn the stakeholder about the long-running tests before they go live.
📢 Use this calculator to determine the needed sample size for your experiment.
📢 Use this calculator to evaluate your test significance and result.
Mistake 5: overlapping A/B tests
Every product team is responsible for its own tests. Often, multiple product teams run various A/B tests at the same time. If you have control over the test timeline (often a product analyst approves which test goes live and when), it’s easy to prioritize the appropriate tests first and communicate the test schedule to PMs. If you don’t have control over the schedule or are pressured under strict deadlines, compromises must be made.
Here is a guide to follow for overlapping tests:
Make sure the same user doesn’t fall into multiple A/B tests. If the testing instrumentation doesn’t support such differentiation, you have to exclude these users from your evaluation.
Make sure overlapping tests evaluate different product metrics. For example, you can focus on retention for measuring one test, but measure payment conversion for evaluating another. If multiple tests are tied to the same metric and with a few tests being successful, you will have a hard time estimating which test contributes to how much increase in revenue or growth.
Watch out for platform overlapping tests (mobile and desktop) which are testing different user flows for the same feature. Often, there is no way to bucket these users into separate groups for A/B tests (prevent mobile users exposed to one experiment from getting into overlapping desktop experiments), so you might have to define user segments and run tests to only the relevant audience.
There are a lot of things to add regarding A/B tests. Some of them can get quite complex, especially during a new product release, where there might not be Baseline metrics ready to compare against. For such cases, make sure you know how to measure product adoption.
I have seen multiple times when a new feature release (the Variant) performed worse than the Control. The new MVP often isn’t optimized yet to perform better or compete with other tested/improved features. This is the case when a qualitative approach (user interviews, surveys, usability testing, etc.) should be added for a new product release and success evaluation.
Also, be prepared for the Variant not to show significant improvement. Often it performs very close to the Control with slight or no difference (especially if your product or feature went through multiple iterations and tests already). Many product teams chase this small 0.05% improvement and spend a lot of time on the test setup, instrumentation, and evaluation. That’s why, as an analyst, you have to understand the test hypothesis, the whole product picture, and the test specifics to provide the right recommendation.
Thanks for reading, everyone. Until next Wednesday!