
Build or Buy: How We Developed A Platform For A/B Tests - Issue 116
Through our wins, challenges, and learnings: A recap of how we developed and launched a new experimental platform.

Hello and welcome to another edition of Data Analysis Journal, a newsletter about data science and product analytics. If you’re not a paid subscriber, here’s what you missed this month:
Ranking The Most Used Features in Your Product Using SQL - how many users are engaging with your product? Are they engaging at all? What are the top used features? A simple SQL solution on how to calculate the most popular (or the most commonly used) user features across all users.
Documentation: How We Do It All Wrong - a guide on how to create, adopt, and maintain documentation in analytics. How to collect and store SQL, Python code, Notebooks, previous analyses, and completed experimentation case studies, and how to structure the process to fuel a proper documentation adoption.
Getting Started With Python Plots - what Python packages to choose for different types of visualizations, a consolidated list of the most useful plot types and plots tutorials, and a quick one-pager that you can refer to while picking a plot for your analysis.
October was busy with dbt + Coalesce in New Orleans, the Elastic Search conference in San Francisco, Big Data + AI conference in Toronto, Google Cloud Next, and The World Ethical Data Forum virtual event.
The spooky month is almost over, and November is promising to go fast with The Data Cloud World Tour in San Francisco and me visiting Berlin!
Today’s topic is a trip down a memory line back to my consulting days when my team developed an experimentation platform for running A/B tests for one of our clients. I will cover our steps, challenges, blockers, and timeline to provide enough perspective for analytical leaders debating whether it’s more appropriate to buy the A/B test tool or build it in-house.
A turbocharged platform with all the features and a blackjack
The objective for our team was to develop an experimentation platform that would work for web and mobile and allow iteration with user flows, copies, CTAs positioning, and layouts.
The product team’s expectations of the new experimentation platform:
Support multiple tests running in parallel.
Support cross-platform testing.
The ability to pause or put a test on hold and then relaunch.
Ease of configuring the test audience, text, and copy.
Ability to target a specific user audience with 20+ properties.
Randomly distributed users across test groups.
Proportional test groups (Control vs Variant) with multivariate functionality.
Ability to exclude users from a specific test.
Flexibility with adjusting traffic volume, launching, pausing, and reverting rollouts.
Live test data monitoring.
View of the test impact on metrics and KPIs.
Ability to exclude test/bot users from the analysis.
It looks (and seemed, at the time) like a demanding list of requirements but in fact, if you work with experimentation data, this is a must-have functionality for any test toolkit to support modern A/B tests. (So if you’re shopping for a good experimentation tool, keep this list handy).
How we developed a new platform
Before I go through the steps, I’d like to remind you that there are 2 main foundational concepts in experimentation:
Randomization - a feature that will pick users randomly and independently from any attributes they possess. We developed our own randomization algorithm that worked based on generating (1) unique experiment keys and (2) hashing logic.
Treatment groups - breaking down your traffic into Control, Variant 1, Variant 2, and others. We achieved this by introducing a set of buckets that would be connected to the experiment keys and hash introduced in the Randownization step.
Our solution was to build a service between the client and the backend that communicated with each other via API calls.
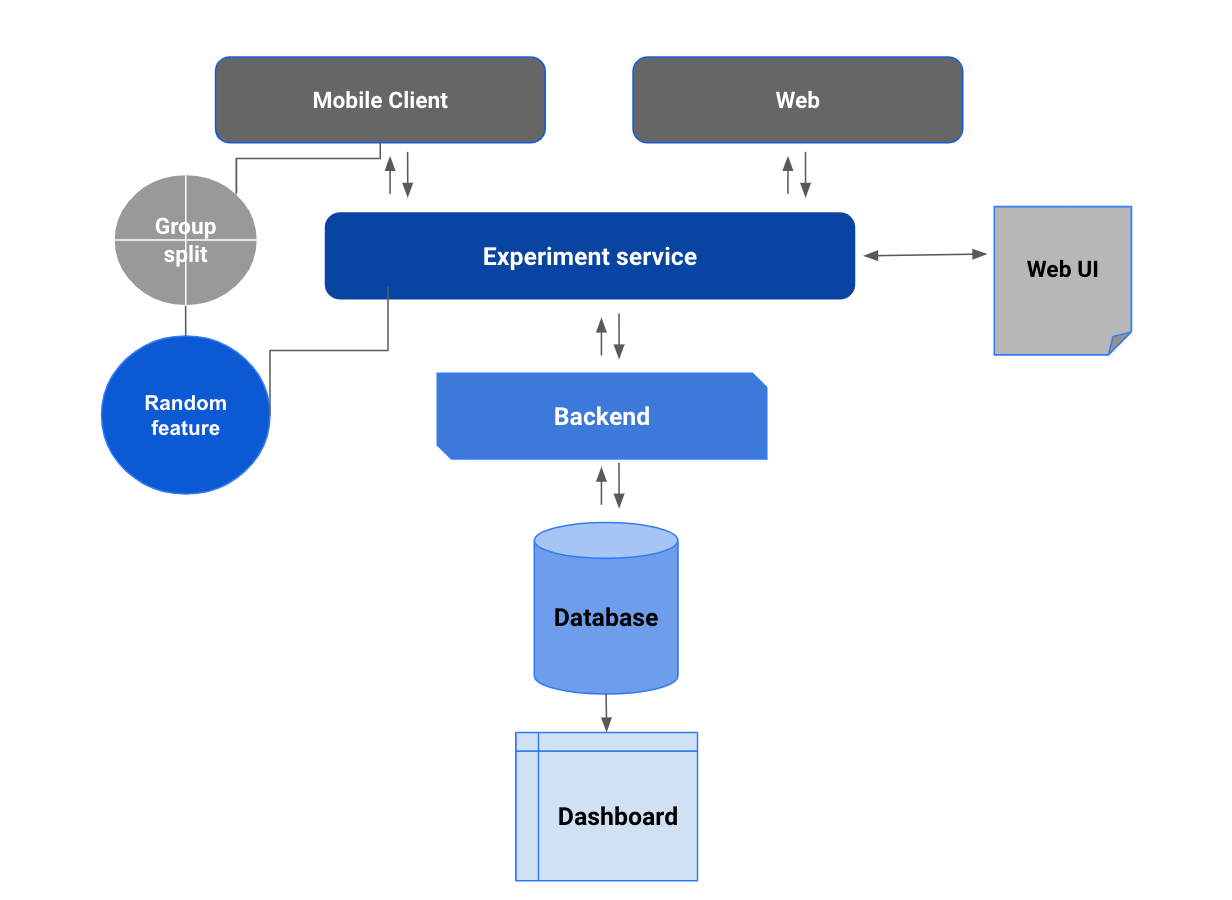
In a very simplified nutshell, our service worked in the following way:
PMs create the experiment/rollout name and specify a list of user (or event) attributes they aim to test using a fancy UI. For example:
experiment_name: webpage_upsell_5d
attributes: user signed >= ‘2022-10-01’, logged in, english-speaking, US, promo-eligible, active, subscribed, completed 5+ successful transactions.
groups: control, variant
Our server receives the given list of required properties and extracts from the backend users (or events) that match given attributes.
The randomization feature kicks in that randomly selects users independently from not-specified-by-PM attributes and characteristics (for example, browser, device, demographics, tenure, number of transactions, etc). These randomized “qualified for the test” users are sent back to the client.
The treatment groups were set on a client side and split received random users into segments: Holdout, Control, Variant 1, Variant 2, and else. Control and Variants must be proportional. The holdout would contain users who are “qualified for the test” but were not selected yet to receive treatment (for example, if the rollout is set to 10% traffic only):


The client would pass the log of experimental events back to a backend, including:
experiment_idexperiment_nameexperiment_groupexperiment_start_dateexperiment_end_date
We loaded this data into RDS and created downstream views that merged these experimental events with user_ids, metrics tables, date series, or whatever analysts worked with to showcase on their dashboards (which I will cover more in one of my next publications hopefully soon!)
The designed architecture seemed straightforward, but we ran into many issues and blockers that affected the process, QA, and by proxy the timeline and budget. We also had to simplify and reiterate some of the features to make sure we met the requirements.
What we did well
Double down on trust and confidence
A trusted platform for A/B testing is vital. If the test is inconclusive or doesn't perform as expected, the testing platform is the first step to blame. That’s why we invested in statistics and QA throughout our development.

Our randomization feature was our “signature” product which we spent a lot of time productizing and testing. The common cause for incorrect or inconclusive A/B tests is the instrumentation limitation to randomly distribute users across multiple properties and attributes. It happens quite often and is very difficult to catch and prove. Teams that develop A/B testing in-house usually treat randomization as an add-on feature without giving much attention to it. What we did differently is that we approached randomization as a complete product itself - with its own development cycle, accuracy and precision scores, QA, and analysis.
As a result, we ensured:
Only qualified users for the test would receive the treatment.
Users would be selected for the test independently from other tests running.
This also allowed us to exclude users from specific tests to minimize overlapping test bias.
The number of inconclusive tests was less than 20% of all other tests running (compared to 65% on their “old” test platform or 50%-80% of the industry average).
Integration with existing analytics
We put a heavy focus on analytics and experiment reading. What I’m most proud of is that we integrated this new platform with their “in-house“ metrics. Given that our service was communicating with their database, we could extract any user or event attributes that our client stored.
As a result:
The experiment impact was simultaneously translated via their custom metrics, aggregated metrics, and their own definitions that were built into the layer of KPIs reporting. It sped up the test read and analysis significantly.
It also unlocked more complex experiments with custom user segments like power users, resurrected users, lagged users, and other personas.
The expected unexpected (or what didn’t go well)
Missing connection with 3P systems
An ancient problem in analytics merging all the sources pushed us back in delivery after we learned that 3P and partners' data related to push notifications, email communications, and that campaign management was not integrated with the client architecture (oh, big surprise).
Our scope was changed from “build a new A/B testing platform” to “bring in all the data, develop dozyllian pipelines and APIs, integrate them and validate, do the cleaning and prepare the foundations, and then build a new A/B testing platform”.
On the good side, developing integrations with 3P and partners' data helped us to catch the red flags with potential blockers in experimentation early on. We got a chance to interview and work with future users of our new platform to better understand their pain points to make sure what we build will work for them. It also helped to make a smoother adoption of a new platform.
High maintenance cost
My team did a great job developing the platform, but as with any data ecosystem, it requires support and maintenance to be scalable and reliable.
What our client didn’t realize is that the complexity of a tool takes a high cost (and expertise) to maintain and keep it running. Given that it was closely integrated into their front-end and back-end, any further migration, optimization, or tuning forced my team to step in to make sure there was no interruption to the user experience or site productivity.
Closing thoughts
I omitted many details in this recap, like real-time configuration change. Our client requested the ability to make changes to the test “on the fly” in real-time without code deployment for every change. After a few discovery sessions, we had to re-scope to address their front-end challenges first to get us there. We also ended up expanding the budget for QA for almost every domain: analytical, data engineering, client, and platform engineering.
As a result, we didn’t start working on a new A/B test platform for at least a year until we brought the necessary 3P and partner data in-house, made changes on their front end to allow real-time experimentation, and optimized a few backend services. Once the foundation was set, building a new testing platform took us 3 development months to make it production ready, and 2 months to set up dashboards for analytics.
Retrospectively, I think the decision for them to develop an A/B test platform in-house was a good one. They had a unique product that required heavy support from both mobile and web, and not many A/B test platforms out there do it well for both. When tests are run in-house, they are integrated deeply into the code, systems, and databases. This is a big advantage for analytics that makes it mature.
That being said, if I were the owner of Olga’s Chocolate&Coffee Night Delivery app, I’d end up buying an A/B testing tool that would allow me to run experiments within minutes after signing the contract. Ironically, it is not always the case, as integration with a new tool can be as complex as developing your own. But that’s a story for another time.
Thanks for reading, everyone. Until next Wednesday!