
Data Science and Analytics at DoorDash | Daniel Parris
Behind the screens of data science at DoorDash: interview with Daniel Parris on his data science journey, career learnings, and writing a newsletter.


Welcome to my Data Analytics Journal, where I write about data science and analytics.
This month, paid subscribers learned about:
Anticipating 2024: Top Trends in Analytics - How to prepare your team for 2024 with top trends and movements in analytics.
How To Run An A/B Test On Low Traffic: What is the minimum number of users needed to launch an A/B test? How do you figure out the trade-off between confidence and test timeline? How can you increase trust in small sample tests?
How To Set Up Subscription Analytics For Growth Reporting - How to develop analytics for subscription growth lifecycle from acquiring data to subscription KPIs reporting.
A few years ago, I interviewed for the Data Science team at DoorDash. At that time, my passion was more focused on growing analytics for B2C. Ultimately, I ended up working at MyFitnessPal. Despite this, I was very impressed with Doordash's Data Science team's efficiency, the complexity of projects, the speed of output delivery, and overall analytics maturity.
When I crossed paths with Daniel Parris, a fellow data scientist-blogger, I knew we should collaborate, and I can’t wait to share my interview with him about his time at DoorDash and his vision for analytics.

Daniel Parris is a data scientist, analyst, and data journalist. He was one of DoorDash's first data science hires, working at the company for nearly six years, and now does consulting and career mentorship.
Daniel is the author of Stat Significant, a weekly newsletter featuring data-centric essays about movies, music, TV, and more. He leverages data storytelling to a new level by tackling different pop culture topics through the lens of data (some of his work was featured by Fandom Entertainment).
Daniel initially majored in film and started his career in the entertainment industry before transitioning into data science. Another reason I appreciate his newsletter is that he integrates his academic interests and passion for pop culture into his professional expertise as a data journalist, creating Stat Significant. That’s what makes it so good.
Below, Daniel shares his journey as a data scientist at DoorDash, discussing his challenges, learnings, and career transition.
Data science today and tomorrow: How do you see it changing? Are there any new trends?
It's trite to say AI will change everything, but I believe AI will change fundamental components of the data science profession. On the one hand, there are the efficiency gains data scientists will reap from the automation of data coding, cleaning, and BI tasks—analysts will be able to work faster. On the other hand, there is a high likelihood that many data scientists will be responsible for building around monolithic black-box AI models. There will be a heavy emphasis on MLOps, assembling and cleaning data that flows into algorithms, and figuring out a way to interpret the outputs of these opaque systems.
The other trend I see in data science is the waning novelty of SQL and Python. Ten years ago, fluency in Pandas and scikit-learn made data scientists highly in demand. Now, there are many resources for learning these skills, or you could use ChatGPT. Technical skills no longer stand out as a unique factor; instead, critical thinking skills, demonstrating the ability to break down and solve complex problems, will become a key differentiator for analysts.
What was your most challenging project, and what were the key learnings from it?
At DoorDash, my most demanding project involved the development of the company's selection intelligence system, designed to identify the most valuable restaurants for the company to focus on.
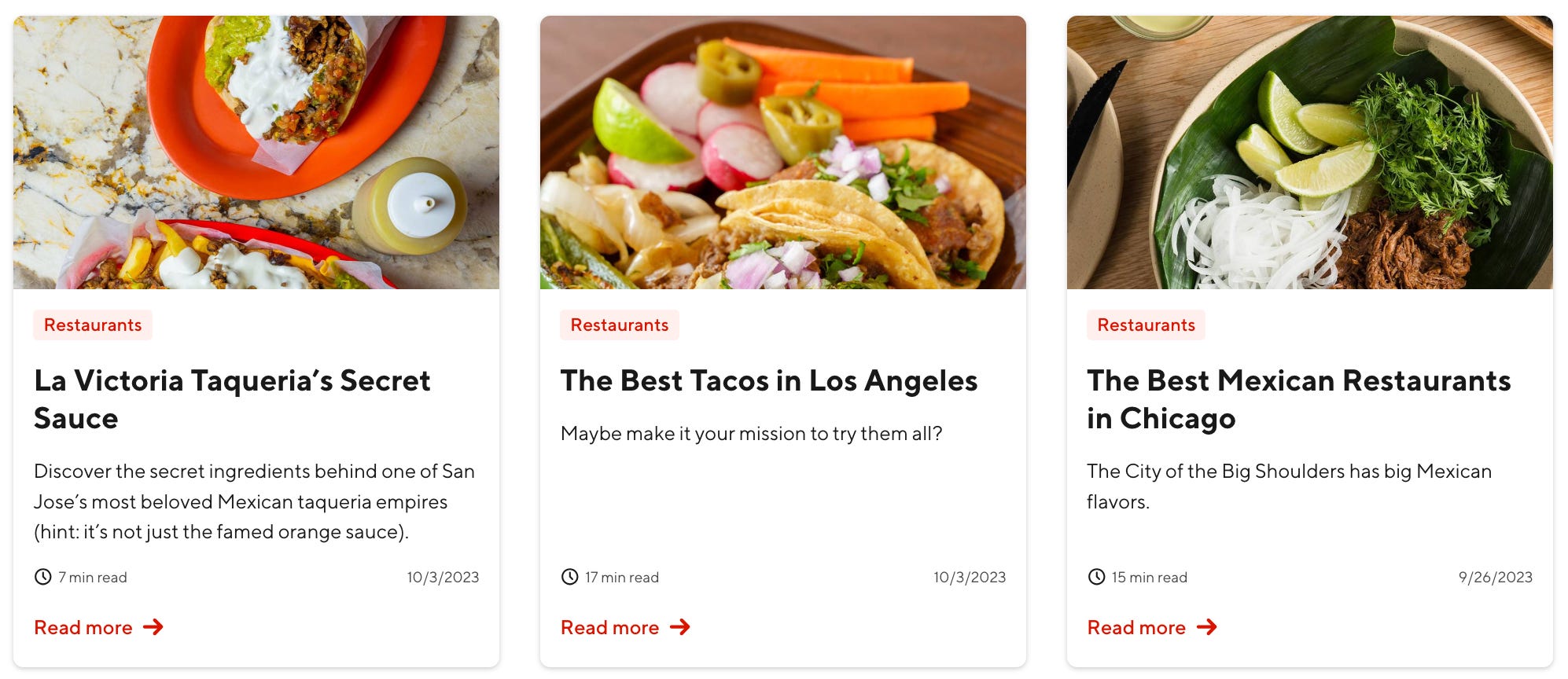
The project necessitated the creation of a predictive model capable of estimating the value of every restaurant in the world (which was as intimidating as it sounds). These estimates would then be packaged for the sales team as leads, and they would attempt to sign the merchants onto the platform. DoorDash viewed its restaurant selection as its number one growth engine, so identifying the best merchants in every market was imperative.
The initiative consisted of three distinct parts:
Creating a database of every restaurant on planet earth and ensuring this repository was up to date with clean data. Every entry had to be accurate—restaurant name, address, and cuisine type—while ensuring these merchants were still in business.
Creating a predictive model that estimated how a restaurant would perform once it was brought on to DoorDash.
Taking these predictions and distributing them to the sales team in a format consistent with the organization's compensation structure.
Ultimately, maintaining a clean repository of every restaurant proved to be the most challenging aspect.
Our initial merchant database came from a stale dataset of extremely low quality. Before we rolled the model out, I wrongly assumed that prediction accuracy would supersede data quality—I was sorely mistaken. The first time we distributed leads, sales reps were pissed. Nearly ten to twenty percent of lead lists were unworkable, either because these merchants were permanently closed or not restaurants at all.
The sales team compiled a spreadsheet of the worst offenders to underscore their frustration. This Google sheet featured over 4,000 offensively bad leads, including strip clubs, consulting firms (McKinsey, Deloitte), dialysis clinics, and other garbage. I had to review the document with the head of sales to explain how this had happened. We spent the next year working on nothing but database quality.
My major learning was to consider the end user of a model or system when launching a project. DoorDash's sales reps did not care about prediction accuracy as much as they cared about having clean, workable leads. I got so invested in building a fancy ML model that I lost sight of how the predictions would be used.
What did the data science team look like in the early days of DoorDash, and how has it changed since then?
The early days were dedicated to building infrastructure. Most projects focused on codifying metrics, creating ETL tables to report these figures, and crafting tools for business partners to view these statistics. The company was highly data-driven in its decision-making and, therefore, emphasized quantifying every aspect of the business. Much of this responsibility fell on to the data science team.
As the company matured, the focus shifted from infrastructure-building to analysis. We had all of this data; we could track the ups and downs of the business, so the top priority became problem-solving. Analysts were called on to identify areas where the company could improve, quantify the potential impacts of strategic initiatives, and then track progress once these projects went live. There was also increased focus on experimentation, with most prominent features subject to an A/B test before launching.
What were the most typical projects?
The most common projects were:
Metric Definition: This work involved creating a new metric, constructing it in an ETL table, and building a dashboard to showcase results.
Measuring Impact: These requests typically concerned the launch of a new feature or initiative. The data science team was asked to quantify the results of these projects through experimentation or lookback analysis.
Identifying Improvement Areas: When there was an obvious problem with the business, an analyst was usually asked to perform a deep dive to ascertain the issue.
Sizing Bets: During quarterly planning, the analytics team sized the impact of potential strategic bets through lightweight modeling.
Was your work stressful?
The first four years of my time at DoorDash were equal parts stressful and exhilarating. We were going up against Uber Eats and Grubhub in a highly competitive space with thin margins, so there was incredible urgency to everything we did. I was also relatively young when I started working at Doordash (23 years old) and was entrusted with the responsibility that may (or may not) have exceeded my career experience—though that was the case with most people. It was a dare-to-be-great situation where you could build crucial infrastructure for a generational company or make a multi-million dollar mistake.
After a while, the work became less stressful. The company achieved scale and had a sufficient headcount to accomplish its goals.
If you had to start over your data journey, what would you do differently?
I majored in film in college and fell into data science a year or two after graduation. So, if I had to start over again, I'd take data science and statistics courses in college. I've suffered from imposter syndrome throughout my career because I lacked the same formal training as other data scientists. Did my atypical background hurt my job performance? Probably not. But it would have helped with confidence earlier in my career.
I still want to take night courses to expand my stats and data science know-how—to learn as much as humanly possible—but I haven't found the time.
Why did you pivot to consultancy? Do you find it more challenging than full-time roles?
I pivoted to consultancy because I wanted more variety in my day-to-day work. Balancing clients of varying subject matter allows me to work on different parts of my brain on a given day. One day, I'll be working on a traditional product analytics task; the next day, I'll be writing a Stat Significant post; and the following day, I could be crafting a loyalty program for a fashion brand. Variety and flexibility are huge upsides to consulting.
Finding clients is challenging, especially when you're an army of one. I've had several meetings where a potential client expresses intense interest, reaching out to arrange the call in the first place, only to have this person completely ghost me. Solo consulting means you must master marketing and sales in addition to analytics. You also have to get used to people ignoring your emails.
Your newsletter is unique and stands out from many. Clearly, you put a lot of work and love into it.
What is your motivation and ultimate goal for your newsletter?
I love data, and I love pop culture. My goal is to spend most of my working hours contemplating movies, music, and TV while combining these passions with my data skillset.
Every week, I get to tackle a fascinating pop culture question in a data-driven manner. Some of my favorite statistical analyses include:
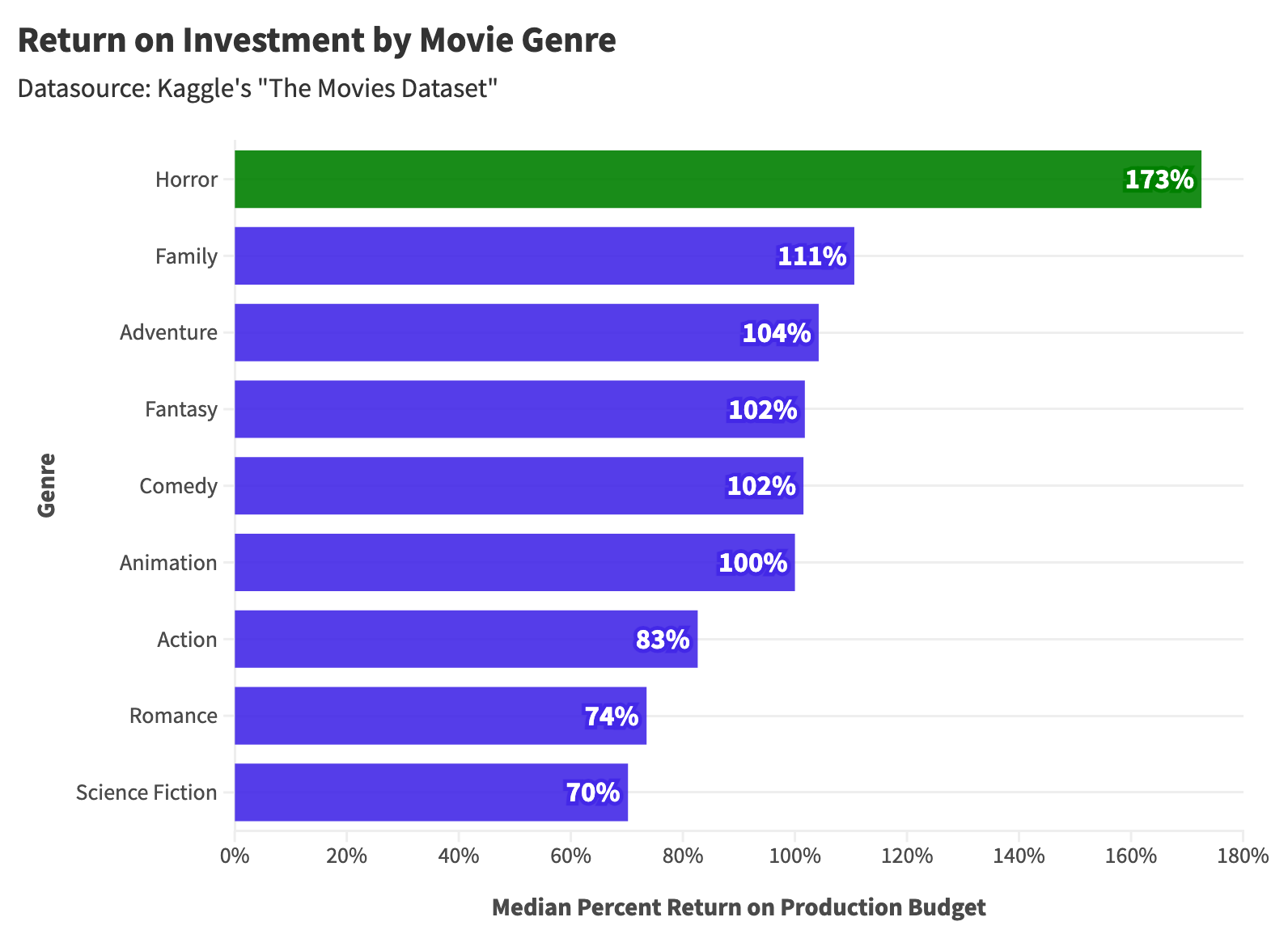
From Why Horror Films are Hollywood's Best Investment: A Statistical Analysis

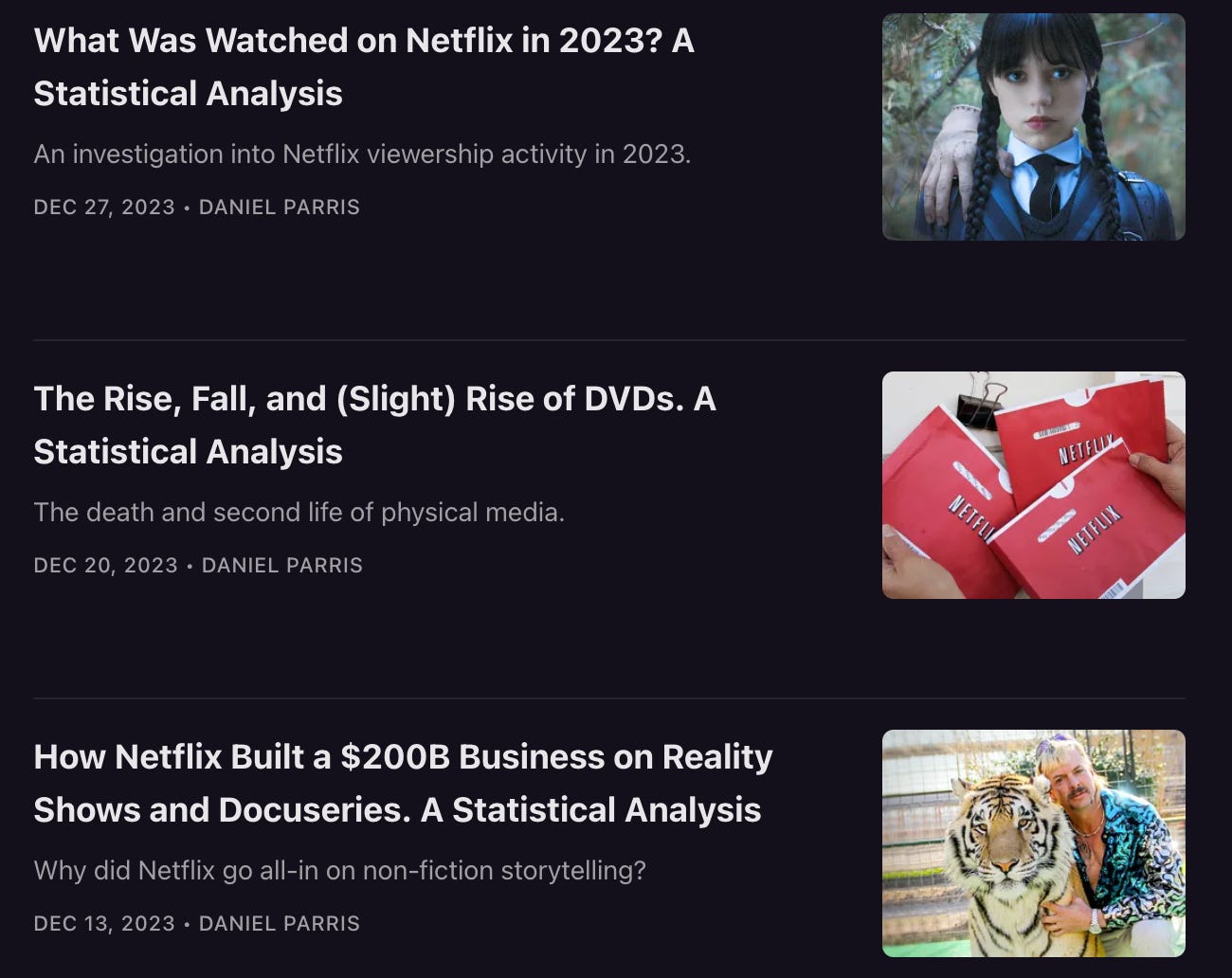
Stat Significant is the fullest embodiment of what's going on in my brain and is a lot of fun to write. My goal is to do the newsletter, or something derivative of the newsletter, full-time.
How much time does it take to write a typical publication, and what is your process?
My writing process usually takes between fifteen and twenty hours per essay. For every article, I have to:
Find a dataset and understand the quirks and structure of the data.
Perform a custom analysis on an unexplored topic.
Graph the findings of my analysis using third-party visualization software.
Research the topic I'm writing about in greater depth and construct a high-level essay outline.
Write an eight to twelve-minute essay, providing readers with a unique data story.
Edit and spot-check my work to make sure it's high-quality.
It's an intensive process, but I believe the work is worth it (or at least I hope it is worth it). I can only manage one essay a week, but I'm optimizing for quality over quantity. My subscribers appreciate each essay's attention to detail and depth, which justifies my hard work.
Is there anything else you want to share to encourage or inspire people to learn data?
Don't be afraid to fail.
Christopher Payne, the former COO of DoorDash, said he learned the most when pushed outside his comfort zone and, thus, actively sought situations where he felt uncomfortable. People don't like discomfort and often associate this emotion with a threat to career stability. That said, if you never try something new, you'll never learn and grow. My failures have facilitated the most impactful learning moments of my career, and I'm now thankful for these mistakes.
Also, failure typically leads to better stories. It's easier to connect over the things that make us human, which is our imperfections.
Thank you, Daniel!
Read some of Daniel’s work:
Connect with Daniel:
LinkedIn: https://www.linkedin.com/in/d-parris/
Reach out at daniel@statsignificant.com
Get mentorship: https://mentors.to/danielparris
Thanks for reading, everyone. Until next Wednesday!
 | A guest post by
|
Interesting stuff