
How To Structure A Data Team - Issue 74
How to structure a data team effectively and set it up for success

Hello analysts! It’s Wednesday, and I’m back with another edition of the Data Analysis Journal newsletter where I write about data analysis, data science, and business intelligence.
If you’re not a paid subscriber, here’s what you missed this month:
Applying Statistics For Data Analysis - statistical concepts you must know for data analysis, how and when to apply them, the difference between the Law of Large Numbers and the Central Limit Theorem, an intro into distributions, and more.
A/B Test Checklist - a short guide to product experimentation steps and must-know terminology. Links to significance and estimation calculators.
The Difference Between Normal and Binomial Distributions - what is the difference between Normal and Binomial Distributions? How do you know when a case calls for Normal or Binomial Distribution?
In December, Instagram surpassed 2 billion in MAU, Amazon Web Services hit an outage, and I did a deep dive into statistics and nailed another batch of ginger cookies. In this newsletter, I want to touch on the subject of structuring data teams and setting them up for success.
Almost a year ago, I published What Exactly Data Analysts Do?, covering 12 different types and flavors of data analyst positions. Every company defines analytics differently. Depending on the industry, domain, company type, size, and budget, your title and certain responsibilities might be different. In my experience of being an analyst, I went through multiple data team iterations and roles. I was part of Data Science, Data Science and Engineering, Product, Engineering, Growth, Growth and Marketing, and even Finance teams. While the main function usually stays the same, the execution, framework, decision-making, and the resulting impact can be quite different.
Each data team iteration I went through had its own pros and cons. Often I was embedded into a specific product unit (or squad) focused on Revenue, Ads, Subscriptions, Creators, Engagement, etc. I was also part of a centralized analytics team.
Regardless of how you structure a team of analysts (centralized or squads), I believe they should be integrated into a core data team. Separating them from data engineering and data science doesn’t make any sense and creates friction and unnecessary blockers.
Separation from data engineering: Once the data engineering team starts treating analysts as stakeholders/requestors instead of partners/peers, that’s when the problem comes. It creates a disconnect between ETLs and the needed data consumed for analysis. The data engineering team, on other hand, relies on analyst input to ensure that data is reproducible and consistent across multiple sources and timezones.
Separation from data science. When different people code the same metric in different ways, don’t expect anything good to happen. Same with an experimental data reading, LTV, Churn, Revenue modeling, or fraud detection. Analysts bring domain knowledge into ML, metrics definitions, and calculations. Data scientists bring precision and accuracy.
Reporting
Reporting is different from the team structure. The team structure speaks about the company organization, but reporting represents the data team impact.
Being data-driven involves developing 3 main capabilities: data strategy, data governance, and data analytics. They evolve into the following hierarchy:
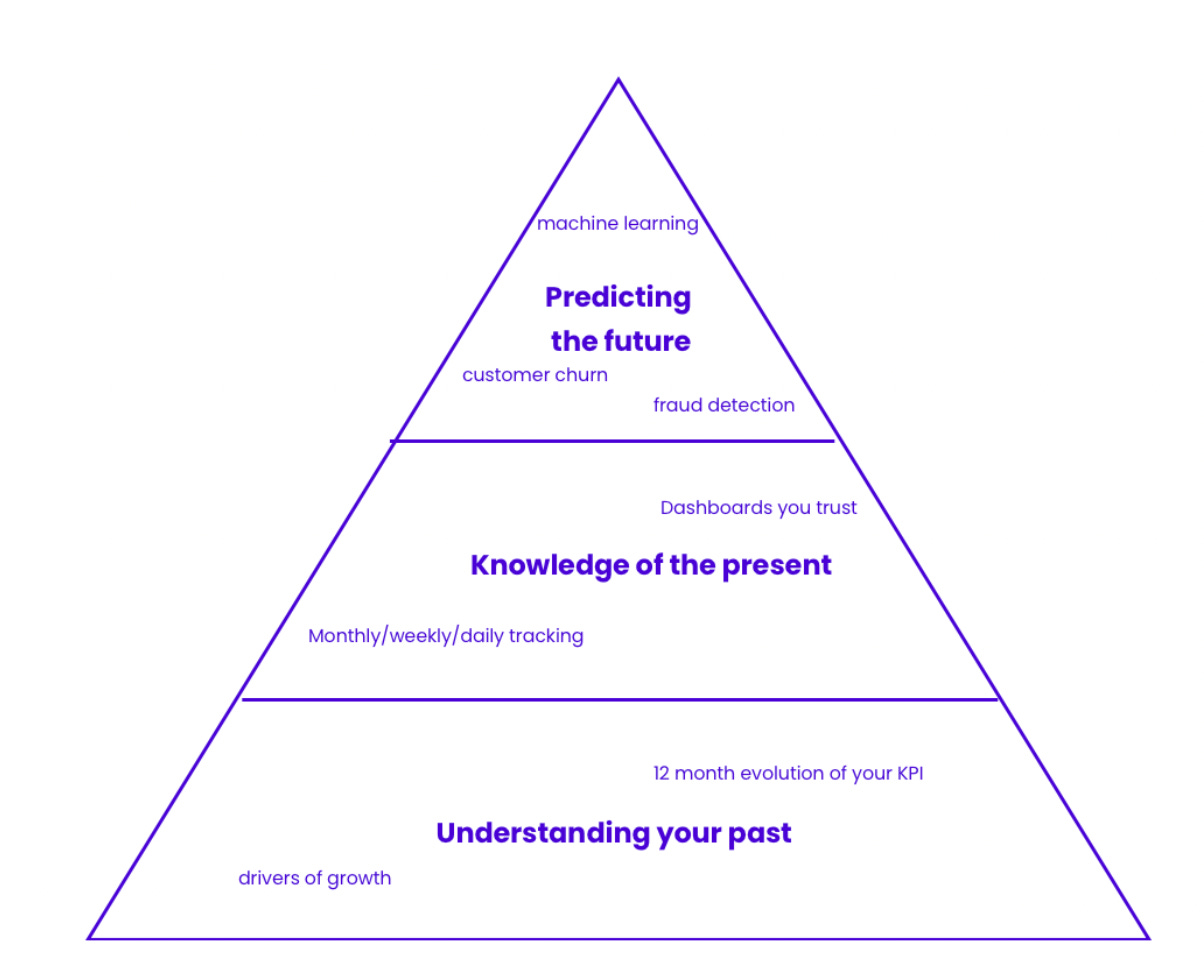
Based on my learnings, I believe that the most successful data team reports to the engineering leadership (either CTO or CDO). Business and product leaders often do not understand data workflow and the nature of data projects. More often than not, the analyst role requires more coding, cleaning, and Q&A than the analysis itself. Often business management sets unrealistic expectations for data quality or visualization without understanding the coding volume of work and dependencies involved. Some of these come down to the process challenges, others to the tool. But getting a new fancy BI tool does not free up analyst time for extra projects.
Here are similar learnings from the Snapcommerce team - How should our company structure our data team?
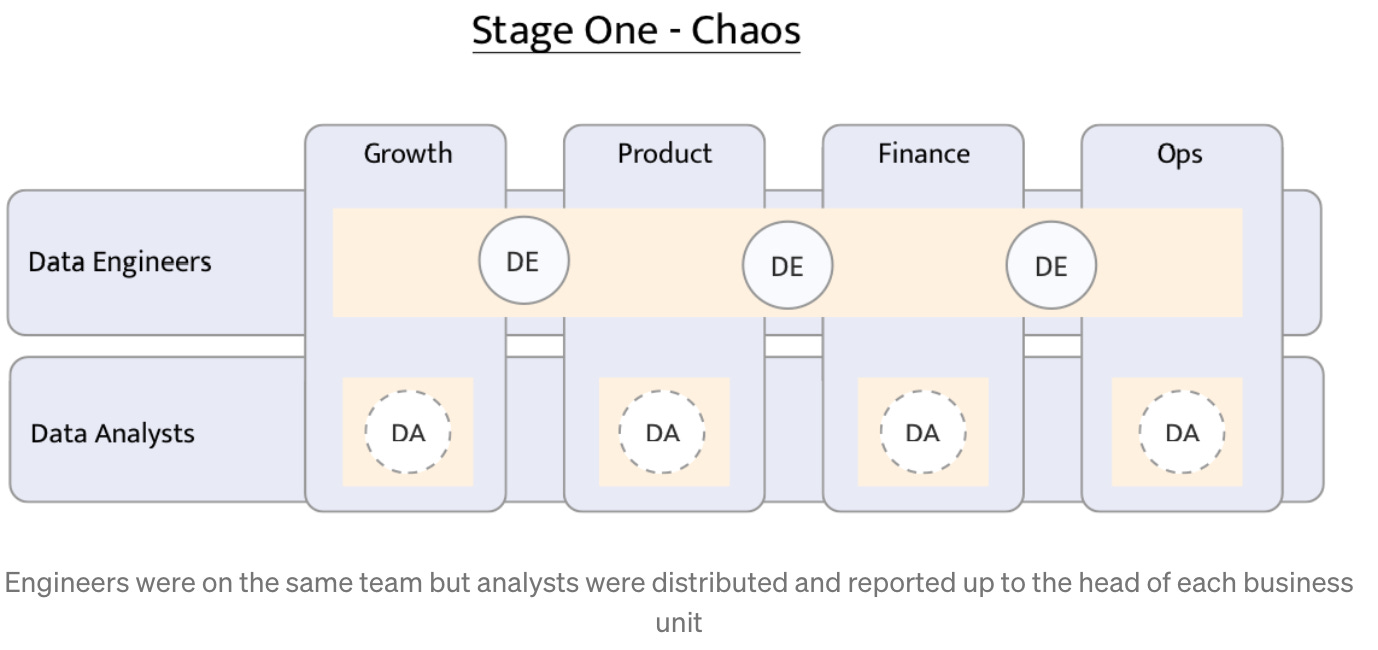
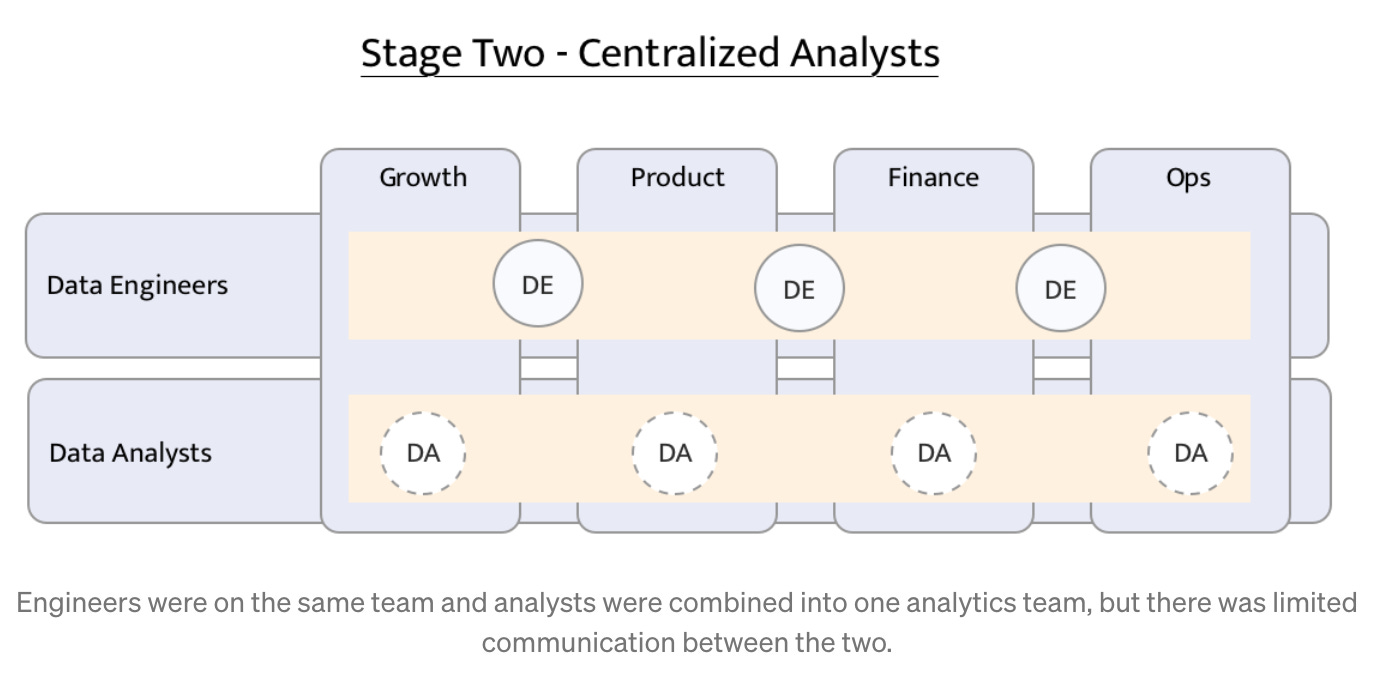
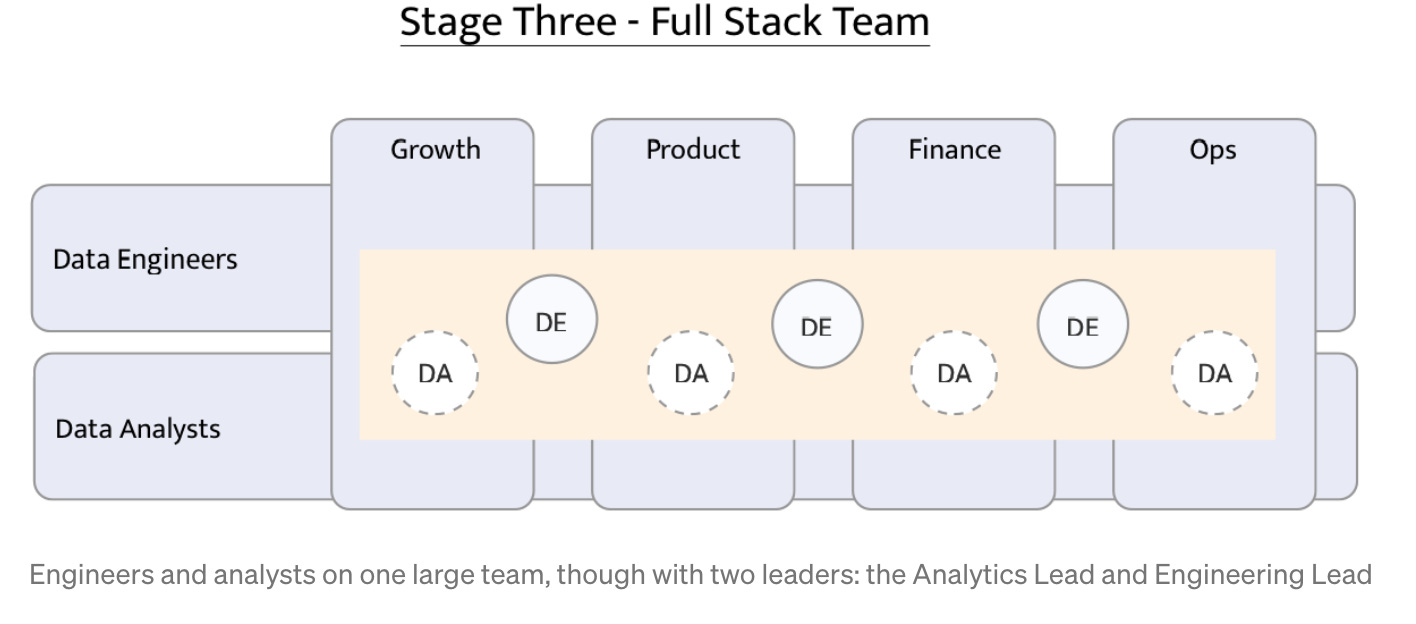
To me, the most successful model which allows analytics to make a visible impact and be efficient is a centralized data team that includes data scientists, data analysts, and data engineers. Such a team manifests data quality, governance, and analytics for the entire organization. All these 3 functions are working in harmony side by side, completing and embedding in each other’s work. Ideally, every DA and DS is focused on a specific product team (Growth, Revenue, Marketing, Engagement, etc). But all of them: DA, DS, and DE, usually share the same KPIs, instrumentation, framework, project management workflow, and documentation. It just doesn’t make sense to split them apart.
🔥 My favorite articles this month
In a response to my last month’s take When Things Go South, a reader shared a recent piece from Simply Statistics - Thinking About Failure in Data Analysis. It echoes some of the challenges I brought up offering solutions. Nicely written, and definitely will be rereading it again.
Andrew Chen becomes philosophical and even more analytical with network effects in this excerpt from his book - Beyond Metcalfe’s Law for Network Effects, and Towards a Better Model.
Reforge published a new piece focusing on Growth and Marketing - When and How to Take Big Swings:
Growth teams are frequently misperceived as optimization squads who run experiments to increase product or marketing KPIs. In reality, the best growth teams are like the best baseball teams. They know when to bunt, when to hit a single, and when to swing big for a home run.”
Check out this recent deep dive into SQL explanation - The difference between WHERE and HAVING. Bookmarking and upvoting.
What is the most-used emoji of the year? The data is here.
📊 Weekly Chart Drop
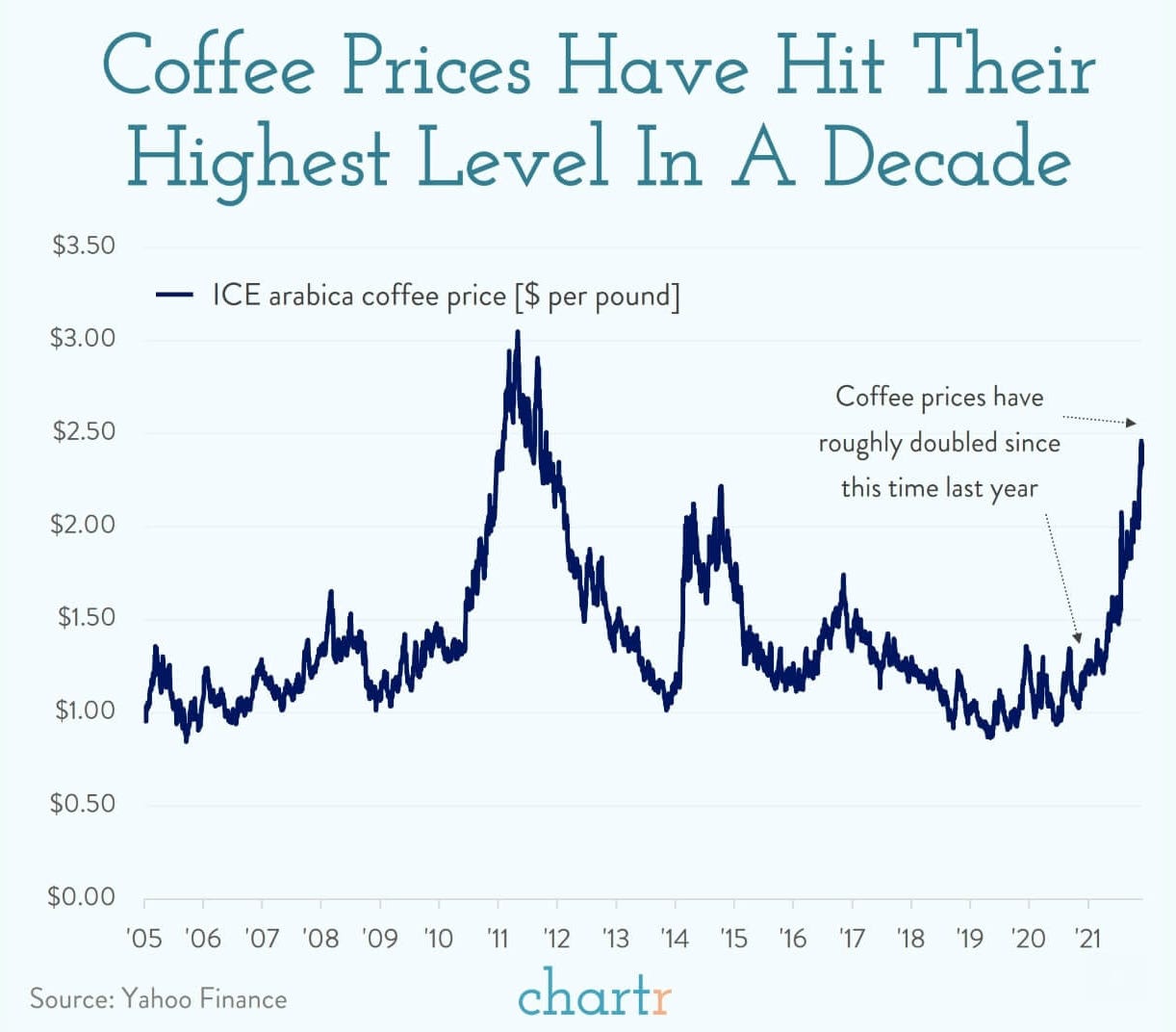
That must be me driving all that surge.
Thanks for reading, everyone. Merry Christmas, and until next Wednesday!