
Behold! How You Can Handle Missing Data - Issue 108
A recap on the proper ways to handle the missing data in your modeling or analysis

Welcome to my Data Analytics Journal newsletter, where I write about data analysis, data science, and business intelligence.
If you’re not a paid subscriber, here’s what you missed this month:
How we optimized the onboarding funnel by 220% - a recap and deep dive into a complete redesign of a user onboarding flow with learnings, data benchmarks, and recommendations.
How To Get Paid Subscriptions In SQL - advanced SQL for extracting and computing missing data to report on premium and growth KPIs. If you work in SaaS or B2B and deal with incomplete transactions/subscription data, this approach will save you many hours.
Engagement and Retention, Part 4: How To Visualize and Read Cohorted Retention - a continuation of the User Engagement and Retention series with a focus on cohorted retention reporting. This time I offer multiple SQL solutions for calculating retention for different business types, visualizing it, and reading different retention charts.
Today I want to do a recap on the most common and, I believe, underrated issue of handling missing values in data analytics and data science.
If your dataset is sparse or incomplete, you already know about 2 main ways to deal with missing values: you either ignore them or input averages instead of N/As and proceed like nothing bad had ever happened. You may also use more powerful methods, e.g forecasting the missing values or applying ML algorithms. In this issue, I want to offer more of a structured approach that will help you recognize situations where it’s okay to ignore N/As for your analysis or when you should do more thorough data cleaning.
*note: this is all assuming that you can’t obtain or acquire the missing data from other sources. If you can, you should do that first and skip this article.
Your approach to handling missing values depends on the following questions:
What are you working on? (e.g. multivariate analysis, regression, ML)
How much data is missing? (e.g. only a few values, critical values, most values)
What is the pattern of missing data? (random, partially random, in pairs, etc)
Ignore or drop missing values:
If your data is missing at random, you can remove NULLs.
If your analysis is multivariate (data containing more than two variables), and if there is a larger number of missing values, then it might be better to drop those rather than do imputation. If the variance is not a factor, you can do it either way.
Deletion can be done listwise (rows containing missing variables are deleted):
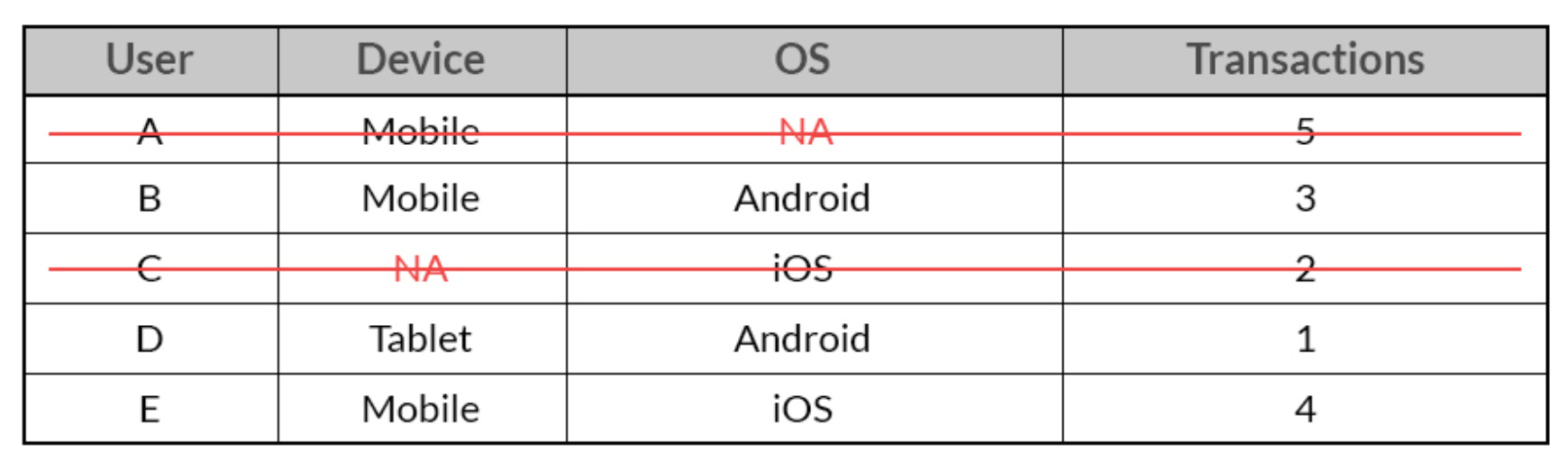
Or pairwise (only the missing observations are deleted):
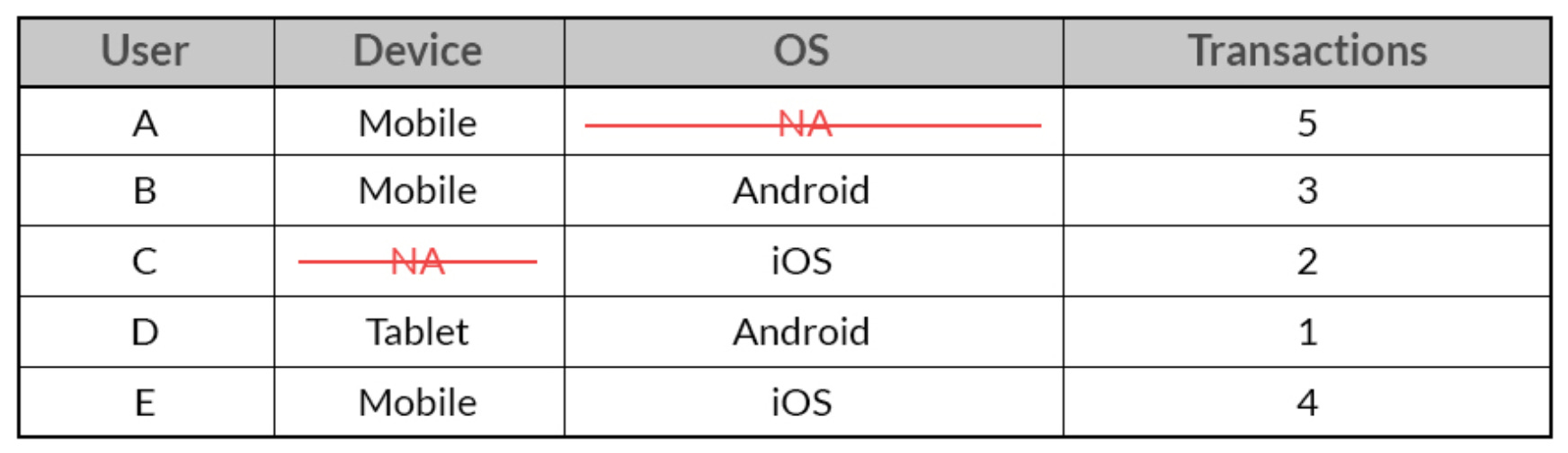
From How to treat missing values in your data
As a rule of thumb, if missing values are random, you can do a T-test for two data partitions: one with missing values and another one without missing values, and check the difference between the 2 means. If there’s no difference, then ignore the NULLs.
If missing values are not random, you are dealing with a more complicated case. Your data might be still randomly distributed within one or more sub-samples. You can also perform regression or nearest neighbor imputation on the column to predict the missing values (I’ll cover more on this in one of my next issues).
Can’t drop missing values, have to impute:
If your analysis is not multivariate, and the values are missing at random, imputation is a good choice, as it will decrease the amount of bias in the data.
If the values are not missing at random, you need to do data imputation.
Check this guide to set up the approach for handling missing values in your analysis:
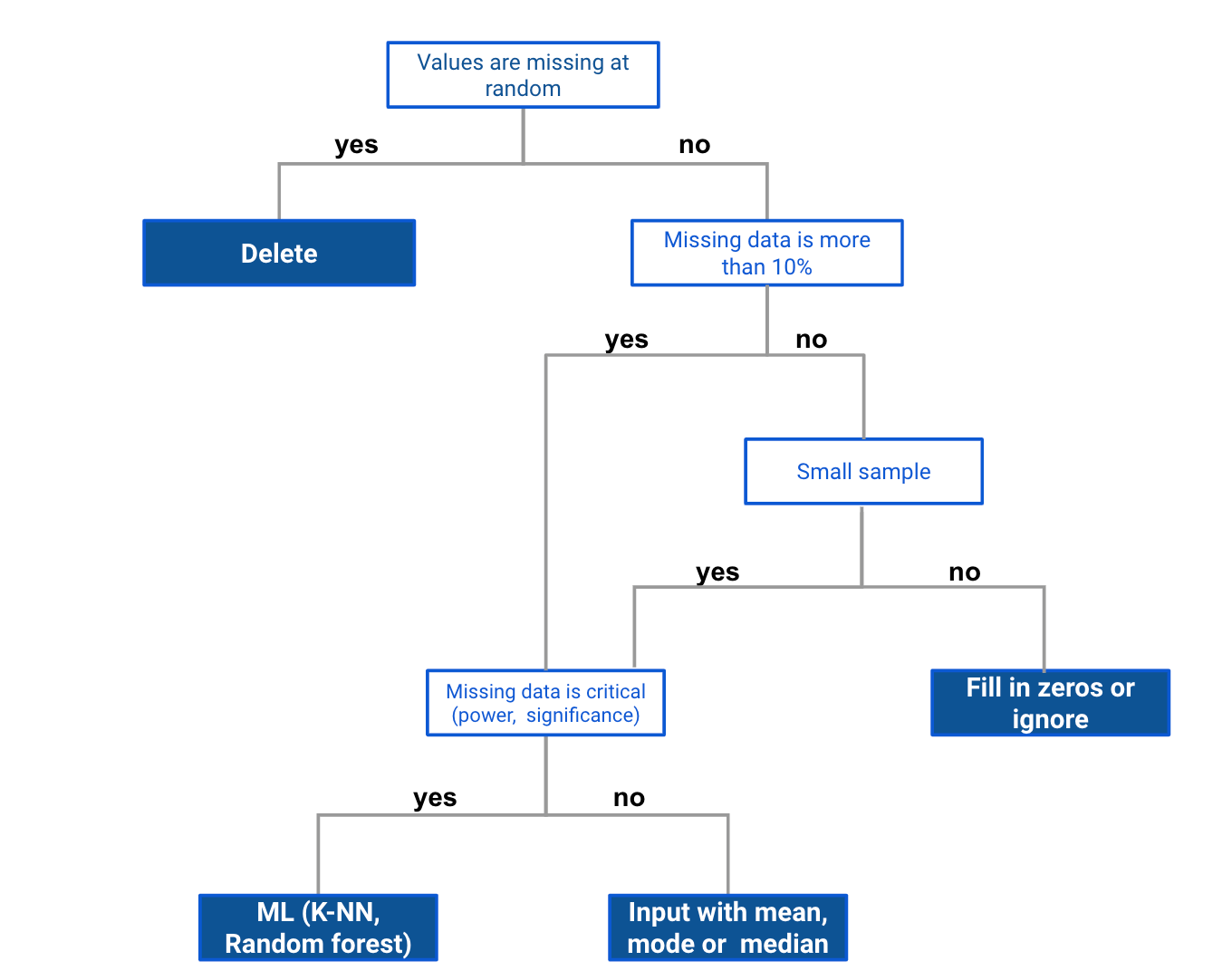
Handling missing values in Python
(pandas, dataframe as df)
df.isnull().sum().sort_values(ascending = False)
If you have to fill in missing values:
df['column']=df['column'].fillna('1') where 1 is the value you want to input
Handling missing values in SQL
In SQL you can leverage DateTime and window functions, and GROUP BY to locate missing values or other data abnormalities. If you have to re-write or input missing values in SQL, you can do it in 2 ways:
During the schema design step, you can set NULL values to 1, for example, or drop the column if needed, rename, or set its parameters.
If you create VIEW, a temporary table with merged datasets, or CTE, you can use a CASE expression to rename or re-define some values.
In your SELECT statement, you can use a CASE expression for data input the same way.
You can use ALTER to run transformations for the already created tables. This probably won’t work if you are dealing with a huge volume of data. Keep in mind that ALTER can be costly.
You can check more Python methods on how to change a data format, input values, and rename fields in my analysis, or in this guide - PostgreSQL vs Python for data cleaning: A guide.
Thanks for reading, everyone!