
The Model Is Smart. Your Company Is the Problem - Issue 322
AI adoption does not fail because models are too weak. It fails because companies are too messy for powerful models to understand.

Welcome to the Data Analysis Journal - a weekly newsletter on data science and analytics.
If you missed the June posts, here’s the roundup:
Omni: The Better Looker, or Just Another Expensive BI Tool? - A deep dive into Omni’s semantic layer, BI-as-code workflow, customer feedback, AI features, and where the tool still falls short.
30 Must-Read Books to Become a Better Analyst or Data Scientist - My collection of books that I believe are essential for becoming a stronger analyst or data scientist, develop analytical intuition and critical thinking.
The Rise of the AI Product Analyst - What AI Product Analysts do, what skills they need, which tools are must-know, and how analysts can prepare for a role that sits between product analytics, data science, analytics engineering, and AI product development.
Last month was… interesting.
First, there was Snowflake Summit, with over 190 booths and more-or-less the same ETL tools everywhere. They even started to sound the same: Datavault, Datalab, Daasity, Daemon, Daman, DataArmy, DataClymer, DataIQ, and 100 more.
Then came Databricks Summit, which was probably the best event I’ve ever been to - both in scale and content. More than 31K attendees! That’s bigger than my hometown.
First of all, I had a chance to meet and interview Ali Ghodsi, CEO & Co-Founder at Databricks. I also joined the launch of a new book, Databricks Data Intelligence Platform by Jason Yip and Marcin Woztyczka. Very good timing, because I’m wrapping up the AI Agent Databricks certification, so it was helpful to have a step-by-step breakdown of the Databricks ecosystem. The book is easy to follow, and I recommend it to anyone working with Databricks products. It’s still free to download, but hurry, it probably won’t stay free for long.
I also interviewed Tristan Handy, CEO & Founder at dbt Labs (my interview is coming soon, and it’s sooo good!). I also spoke with the Omni team (yes, they saw my Omni review. Yes, it was a little awkward), and I spent time with the Hex team.
This newsletter reflects my recent conversations with leaders from Databricks, Informatica, and Salesforce about AI hype vs AI’s real impact on analytics and BI.
Below, I want to demystify a few AI myths affecting data and analytics. And this time, the discussion is finally backed by early AI benchmarks that show the gap between leadership ambition - becoming “AI-native”, pushing everyone toward “AI engineering”, and demanding AI-driven work, and the actual state of things inside companies.
Before I continue, I want to acknowledge how fortunate I am to speak with and learn from the people contributing to this publication - Ali Ghodsi - CEO of Databricks, Manouj Tahiliani - SVP of Salesforce, Gaurav Pathak - SVP Product Management AI and Metadata at Salesforce, and many others. Years ago, I would not have imagined that a personal analytics newsletter could become a bridge to conversations with some of the strongest practitioners and builders in data and AI. I’m grateful for the access, the learning, and for all of you who continue to read this somewhat private journal on where analytics is going. Thank you for being here ♥️
Data platforms are shaping analytics
I liked Databricks Summit this year, and I also enjoyed Informatica World a few weeks earlier, because both conferences opened with transparency and a reality check:
Garbage-in is garbage-out: your data quality is the foundation for your AI.
AI maturity and AI success directly depends on your data management: your ability to maintain metadata and context. And context comes with a cost - often a tremendous cost, and there are no shortcuts.
That is exactly what I have been arguing for a long time. In analytics and BI (especially in analytics and BI!), you get what you pay for. Investment in data governance, data quality, metadata, lineage, and business definitions goes a long way when companies try to build self-serve analytics or integrate AI into their systems. You cannot build real intelligence on top of incomplete 3rd data, disconnected tools, or knowledge sitting in people’s heads. Sooner or later, it all comes back to the importance of having a strong data management platform - and that still requires a strong team of data experts.
Myth 1: Everyone is using AI
No, they are not. Everyone is talking about AI: many companies are buying AI tools, launching pilots, adding copilots, and telling employees to become “AI-driven”. But that is not the same as AI being embedded into how work gets done.
The Databricks benchmark report shows a perception gap:
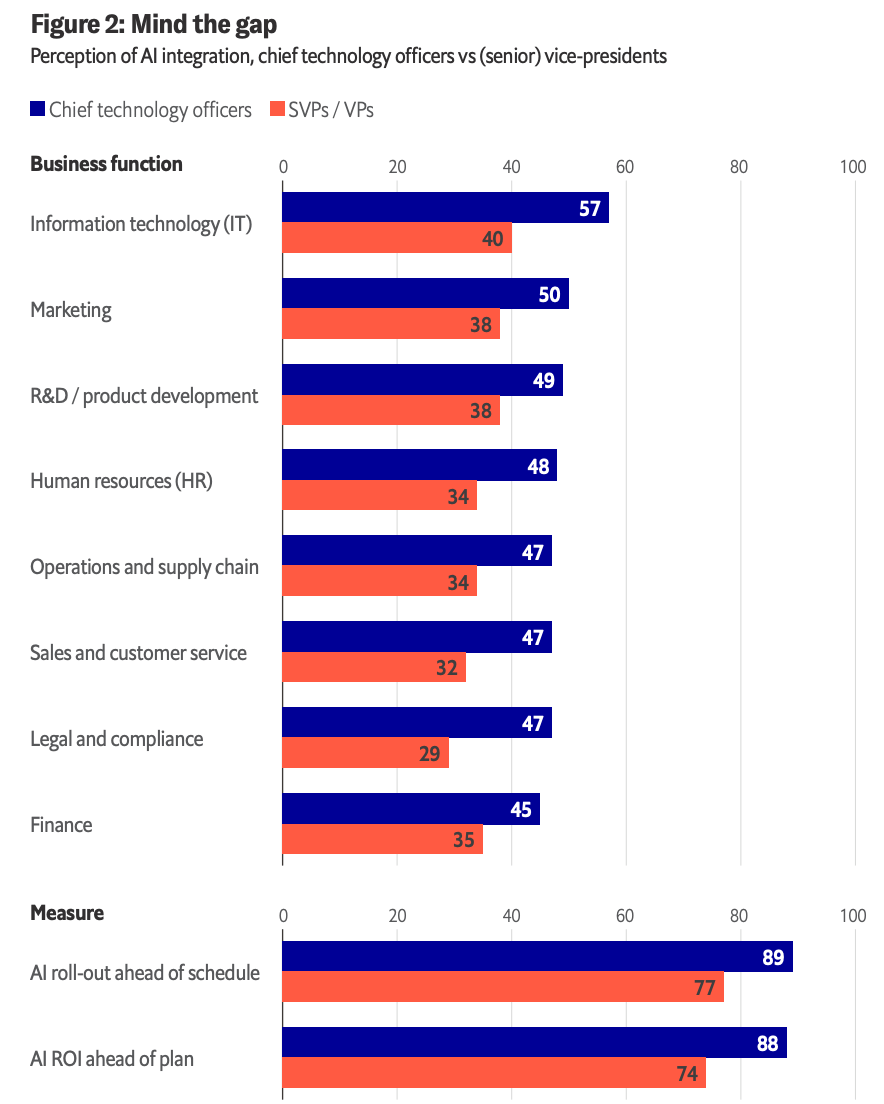
CTOs are much more optimistic than the people closer to execution. 89% say AI rollout is ahead of schedule, but only 77% of VPs agree.
And even when companies say they are adopting AI, the underlying work often has not been redesigned enough to support it:
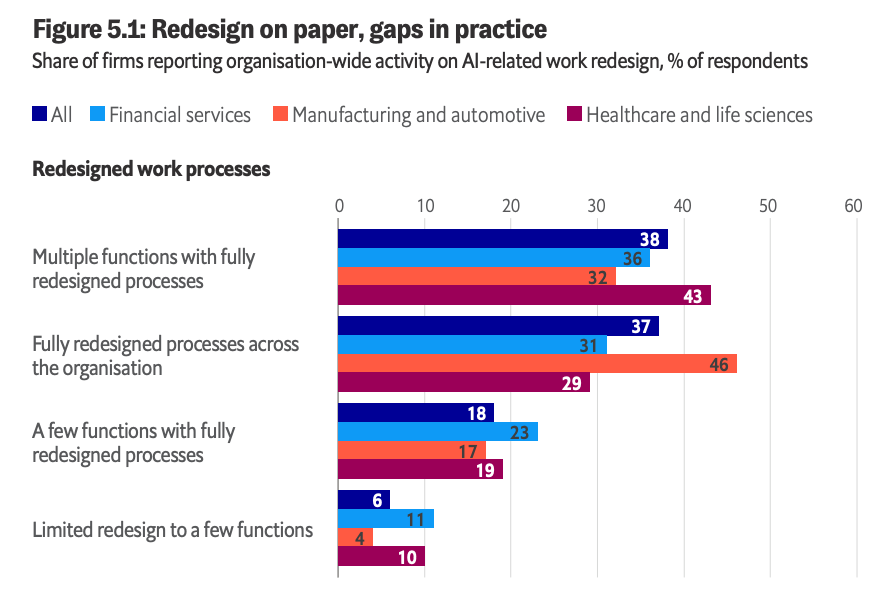
Only 37% of firms say they have fully redesigned processes across the organization. Another 38% say multiple functions have redesigned processes. That still leaves a lot of companies layering AI on top of old workflows, old incentives, old data problems, and old governance gaps.
Myth 2: Better model, better answers
There are so many models now:
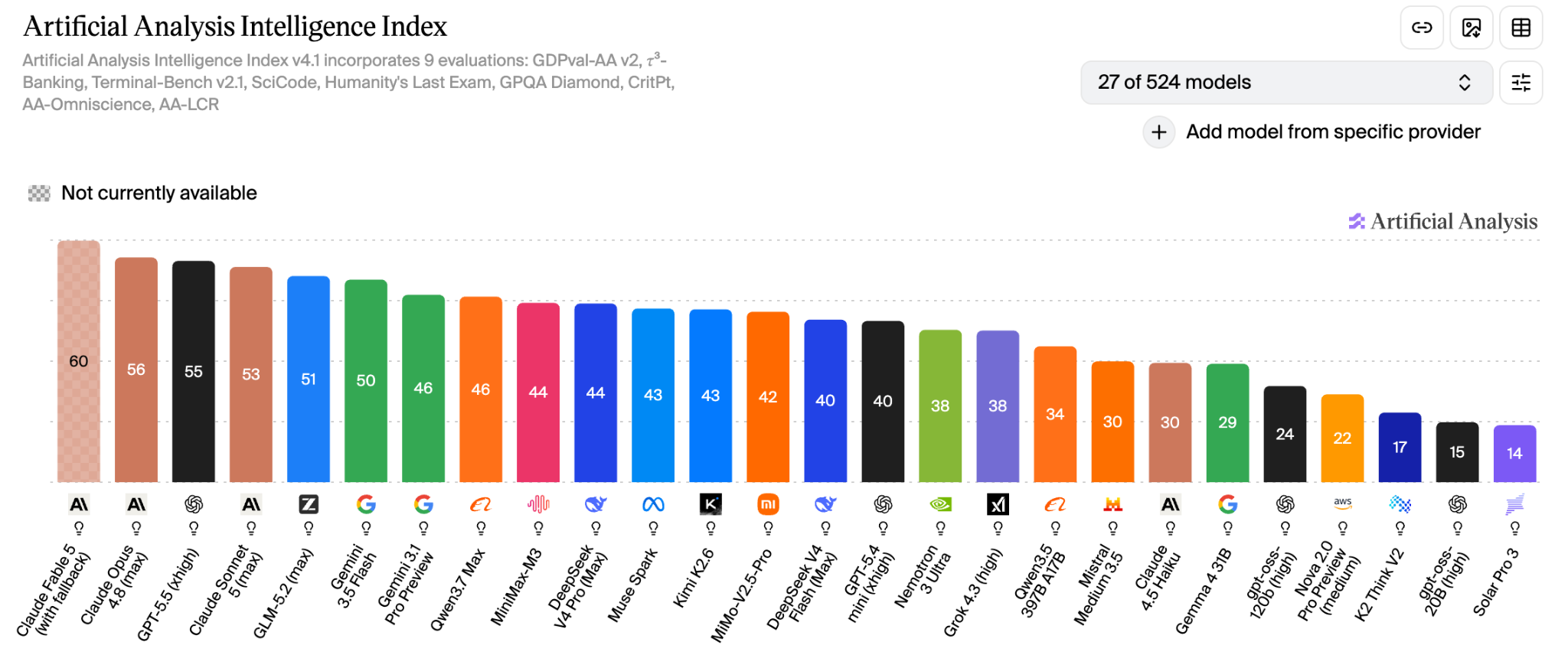
One of the common myths is that analytics, BI, and self-serve data get better as models get smarter. It sounds logical - if the model can reason better, write SQL better, and summarize better, then the answers should improve, right?
Wrong. It is often the opposite. Smarter models expose and break over the company’s missing context, messy data, weak governance, while skyrocketing the cost:
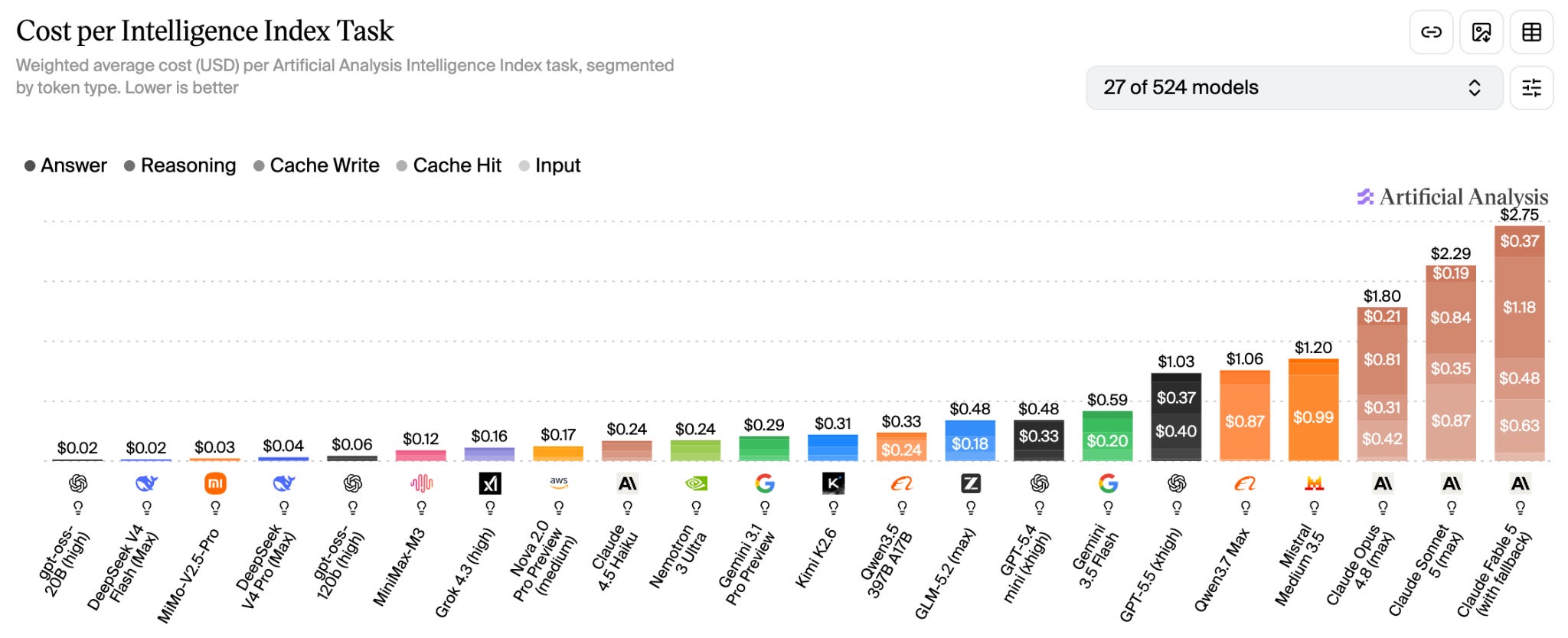
A model can reason only over the context it receives. If the company’s data is fragmented, definitions conflict with each other, no metadata, and source-of-truth logic lives nowhere, the model is failing. The more advanced model, the more it relies on the context.
This is why the semantic layer conversation is so back everywhere now. AI makes missing semantics very painful. If someone asks for “customer data,” a public model does not know whether “customer” means a company, an individual, a B2B account, or a B2C buyer or particular user_id. That meaning lives in the catalog, the glossary, the MDM layer, and the semantic layer - not inside the model by default.
So AI is likely to fail not because the model is not smart enough, but because companies are not organized enough for powerful, sophisticated, and expensive models to understand them.
Myth 3: Ten agents are cheaper than one human
The idea that companies can replace repetitive human work with agents and automatically save money is dangerously incomplete.
Agents can reduce some human work, but they also create new machine work. They read more data, call more APIs, query more systems, create more logs, generate more code, trigger more workflows, and require more monitoring. The cost problem is massive data usage. And agents are designed to increase that usage.
The benchmark report confirms that for AI agents, cost and resource constraints are one of the biggest barriers to scaling. Every autonomous action creates data that may need to be logged, stored, monitored, and sometimes audited. Agents also require more computation than traditional generative AI, which adds more cost.
Agents need data access, permissions, context, identity management, monitoring, observability, lineage, evaluation, cost controls, and governance. Many companies underestimate how much they consume infrastructure:
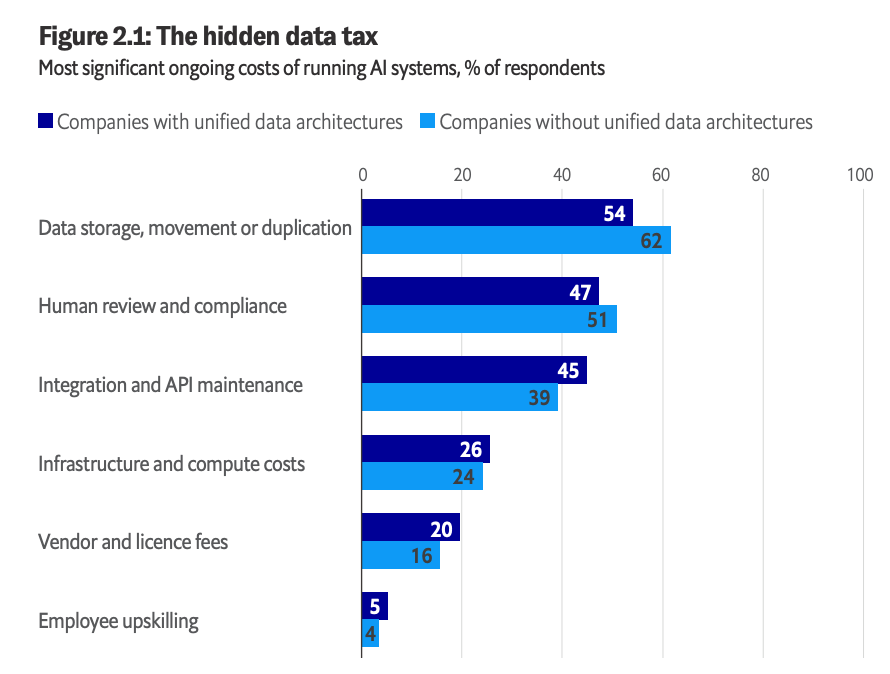
This also changes how we should think about AI code generation. If AI writes much more code over the next year, that code still needs to be stored, reviewed, secured, versioned, governed, maintained, and eventually deleted. Otherwise companies will create a new layer of technical debt faster than they can understand it.
Agents put real pressure on infrastructure. If usage triples, the cost goes up, even if the users are agents and not humans. Companies need to think about this now. They need to invest in context management, model routing, filtering, and systems that can separate useful output from noise.
Cost is already going through the roof for many teams. To control that cost while still investing in AI means knowing which models to use for which tasks: simple models for simple work, heavier models for important or high-risk work. Agents need that context too.
Myth 4: Accuracy is static
If you ask a model a reasoning question and it performs well, it is natural to trust it the next time. That is one of the biggest AI dangers: one accurate answer does not guarantee the next answer will be also accurate.
AI accuracy is an operating dynamic condition, not a fixed product feature.
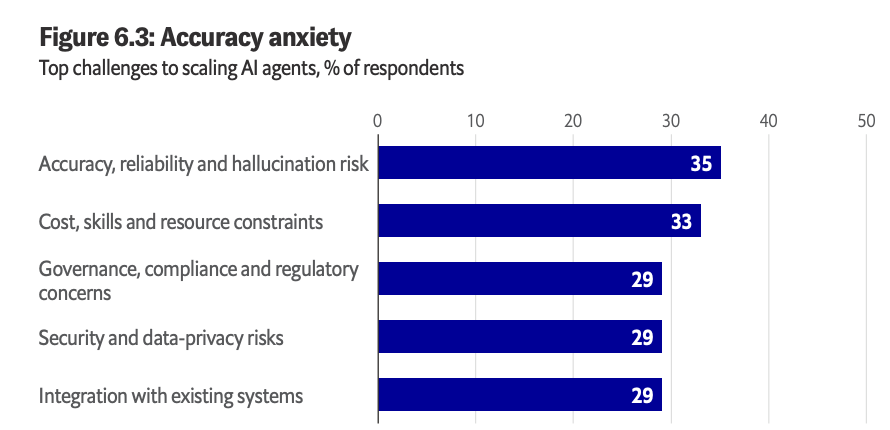
The quality of AI output has to be maintained over time to address changes in data, business rules, definitions, permissions, models, user behavior or systems:
“About three in five firms review AI systems during development and before deployment. Fewer than two in five continue that oversight after a system goes live—the stage where AI models drift, data shifts and edge cases multiply. Worse, one in eight firms reviews governance only when something goes wrong.”
Anthropic says agentic analytics accuracy drifts 95% → 65% in a month without maintenance. But maintaining model quality output is not something teams scope time for, but this one is critically important: a model that summarizes a meeting incorrectly is annoying. A model that changes a customer segment incorrectly is expensive. But an agent that takes action based on outdated, incomplete, or unauthorized data is a governance incident.
This is why AI quality needs to be maintained like a production system. Teams need recurring evaluation, post-deployment monitoring, data freshness checks, drift detection, incident review, escalation paths, and analysts who are trained to question the system.
Gaurav Pathak from Informatica made a good point about governance: “Many companies start by focusing on building the best agent, but governance has to be considered at the beginning of the cycle. Otherwise agents may take private customer information or brand-sensitive information and make it available to people who should not see it.”
This is where many companies are still stuck in an old governance mindset ,where governance is treated like a document, a checklist, an Excel sheet of approved models, or a wiki page of certified or golden datasets. That worked in the dashboard era, but it is not enough in the agent era. Agents need governance that is executable, systematic, embedded, and available where the work happens.
Myth 5: More agents means more impact
More AI code or agents does not automatically mean more AI impact, like more pilots do not mean more value.
Based on benchmark report, high AI activity can hide very thin returns:
“In 2026, high levels of AI deployment mask thin returns. Our survey finds that more than four in five executives say their AI programmes are beating expectations. Yet only about two in five firms formally require teams to track business impact, from cost savings to revenue and efficiency”
That means many companies are busy with AI, but far fewer can prove that AI is changing the business.
You can count AI-generated code, prompts, pilots, tools, dashboards, copilots, and agent workflows. But none of that proves business value. It should go down to what changed:
Did costs go down or did cycle time improve?
Did revenue go up? Or did customers get a better experience?
Did employees actually save time, or the company just created another tool they have to manage?
From my interview with Gaurav Pathak, professionals still spend around 80% of their time getting data into the right shape - cleaning it, preparing it, governing it, and making sure it is fit for purpose.
From the benchmark report, a few examples how teams quantify AI impact:
Stellantis cut its AI portfolio to 20 programs, each required to show measurable value within 12 to 18 months. Suncorp started with 120 AI ideas, narrowed them to 20, and killed several that could not justify their cost. One of Suncorp’s selection rules was reuse: build once, deploy many times.
Myth 6: Tools or tech determine whether AI scales
No. Culture does.
The hardest part of making AI work is rewiring the organization around them: redesigning tasks, training people, changing workflows, creating the right incentives, and making it safe (and encouraging) for employees to question AI output.
The benchmark report points to a major mismatch:
“Half of firms cite human review as a top ongoing cost, yet only 4% point to employee upskilling. Firms are wrong to think that they can keep AI running without investing in the people who must work alongside it”
Changing work is harder than changing job descriptions.
This is why I keep coming back to data platforms and data teams.
AI makes weak data work more dangerous. In the dashboard era, bad data created bad reports. In the agent era, bad data can create bad decisions, bad customer actions, data leaks, compliance failures, and uncontrolled cost.
The future of analytics depends on whether companies can build and maintain trusted context around those models, which means better governance, matured semantic layers, cost controls and monitoring, and yes - better data teams.
Thanks for reading, everyone! Until next Wednesday!